----------------------------------------------------------------------------------------------------------------------------------------------------------------
원문 : http://www.zdnet.co.kr/news/news_view.asp?artice_id=00000039137247&type=det
----------------------------------------------------------------------------------------------------------------------------------------------------------------
파티셔닝 세계 입문
대용량 테이블이나 인덱스를 파티셔닝한다는 것은 하나의 Object를 여러 개의 세그먼트로 나눈다는 의미이다. 즉 하나의 테이블이나 인덱스가 동일한 논리적 속성을 가진 여러 개의 단위(partition)로 나누어져 각각이 PCTFREE, PCTUSED, INITRANS, MAXTRANS, TABLESPACE, STORAGE PARAMETER 등 별도의 물리적 속성을 갖는 것이다.
특히 관리해야 할 데이터가 늘어나면 성능과 스토리지 관점에서 문제가 생길 수 있는데, 이를 해결할 수 있는 효율적인 방법 가운데 하나가 곧 파티셔닝이다. 파티셔닝은 보통 다음과 같은 장점을 갖고 있다.
◆ 데이터 액세스시(특히 풀 스캔시) 액세스의 범위를 줄여 성능을 향상시킨다.
◆ 물리적으로 여러 영역으로 파티셔닝해 전체 데이터의 훼손 가능성이 줄어들고 데이터 가용성이 향상된다.
◆ 각 파티션별로 백업, 복구 작업을 할 수 있다.
◆ 테이블의 파티션 단위로 디스크 I/O를 분산해 부하를 줄일 수 있다.
오라클 DBMS에서 제공하는 파티셔닝 방식에는 레인지(range) 파티셔닝, 해시(hash) 파티셔닝, 리스트(list) 파티셔닝, 컴포지트(composite) 파티셔닝(레인지-해시, 레인지-리스트) 등이 있다.
특정 컬럼 값을 기준으로 분할하는 레인지 파티셔닝
레인지 파티셔닝은 어떤 특정 컬럼의 정렬 값을 기준으로 분할하는 것이다. 주로 순차적인(historical) 데이터를 관리하는 테이블에 많이 사용된다. 예를 들면 ‘가입계약’이라는 테이블이 있고 여기에 몇 년 동안의 데이터가 쌓여 있다면, 보통 5년치 데이터만 관리하고 이 가운데 자주 액세스하는 하는 것은 최근 1~2년 정도가 일반적이다.
따라서 이를 년별, 월별로 파티셔닝하고 애플리케이션의 SQL을 조정해 전체 데이터가 아닌 최근 정보를 가지고 있는 파티션만 액세스하도록 하면 전체 데이터베이스의 성능을 향상시킬 수 있다. 일부 사례의 경우 가입계약_1999, 가입계약_2000처럼 월별 또는 년별로 테이블을 따로 만들어 사용하기도 했지만 실제로 쓰는 데 불편한 점이 많고 액세스하는 SQL이 복잡해지는 단점이 있다. 다음은 레인지 파티션을 만드는 DDL(Data Definition Language) 스크립트다.
CREATE TABLE CONTRACT
(I_YYYYMMDD VARCHAR2(8), I_CUSTOMER VARCHAR2(9), …… )
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0)
PARTITION BY RANGE (I_YYYYMMDD)
(PARTITION PAR_200307 VALUES LESS THAN (‘20030801’),
PARTITION PAR_200308 VALUES LESS THAN (‘20030901’), …… )
PARTITION BY RANGE (COLUMN_LIST)는 특정 컬럼을 기준으로 파티셔닝을 할 것인지를 결정하는 것이고, VALUES LESS THAN (VALUE_LIST)는 해당 파티션이 어느 범위에 포함될 것인지 상한을 정하는 것이다. PARTITION BY RANGE에 나타나는 COLUMN_LIST를 파티셔닝 컬럼이라고 하며 이 값이 파티셔닝 키를 형성한다.
파티셔닝 컬럼은 결합 인덱스처럼 최대 16개까지 지정할 수 있다. VALUESS LESS THAN에 나타나는 VALUE_LIST는 파티셔닝 컬럼들의 상한 값으로, 여기 지정된 값보다 작은 값만을 저장하겠다는 의미이다. 이런 스크립트에서 지정한 물리적 속성들은 각 파티션들이 생성될 때 개별적으로 물리적 속성을 지정하지 않으면 각 파티션들은 이러한 속성 값을 적용 받게 된다.
오직 성능 향상, 해시 파티셔닝
해시 파티셔닝은 특정 컬럼 값에 해시 함수를 적용해 분할하는 방식으로, 데이터의 관리 목적보다는 성능 향상에 초점을 맞춘 개념이다. 레인지 파티셔닝은 각 범위에 따라 데이터 양이 일정치 않아 분포도가 일정치 않은 단점이 있는데, 해시 파티셔닝을 이런 단점을 보완해 일정한 분포를 가진 파티션으로 나누고, 균등한 분포도를 가질 수 있도록 조율해 병렬 프로세싱으로 성능을 높인다. 실제로 분포도를 정의하기 어려운 테이블을 파티셔닝을 할 때 많이 이용하고 2의 배수 개수로 파티셔닝하는 것이 일반적이다.
해시 파티셔닝으로 구분된 파티션들은 동일한 논리, 물리적 속성을 가지다(단 테이블스페이스(tablespace)는 유일하게 파티션별로 지정할 수 있다). 또한 레인지 파티션과 달리 각 파티션에 지정된 값들을 DBMS가 결정하므로 각 파티션에 어떤 값들이 들어 있는지를 알 수 없다. 그러나 대용량의 분포도가 일정치 않은 테이블을 마이그레이션할 때는 프로그램 병렬 방식과 함께 유용하게 사용할 수 있다. 다음은 해시 파티션을 만드는 DDL 스크립트이다.
CREATE TABLE CONTRACT
( SERIAL NUMBER, CODE VARCHAR2(4), ……)
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0)
PARTITION BY HASH(SERIAL)
(PARTITION PAR_HASH_1 TABLESPACE TBS2,
PARTITION PAR_HASH_2 TABLESPACE TBS3, ……)
함께 쓰일 때 더욱 강력한 리스트 파티셔닝
리스트 파티셔닝은 특정 컬럼의 특정 값을 기준으로 파티셔닝을 하는 방식이다. 주로 이질적인(distinct) 값이 많지 않고 분포도가 비슷하며 다양한 SQL의 액세스 패스에서 해당 컬럼의 조건이 많이 들어오는 경우 유용하게 사용된다. 예를 들어 ‘서비스 계약’이라는 테이블이 있고 서비스를 최초 가입한 대리점을 ‘가입 대리점’, 변경사항을 처리한 대리점을 ‘처리 대리점’이라고 한다면 모든 서비스의 가입, 해지, 전환 등의 처리 데이터에는 이 두 대리점이 존재한다. 테이블 구조를 보면 다음과 같다.
CREATE TABLE SERVICE_CONTRACT
(I_YYYYMMDD VARCHAR2(8), I_CUSTOMER VARCHAR2(6),
I_DLR_IND VARCHAR2(2), I_DEALER VARCHAR2(6), ……)
즉 I_DLR_IND(대리점 구분)라는 컬럼이 존재하고 ‘A’일 때는 ‘가입 대리점’, ‘S’일 때는 ‘처리 대리점“이라고 할 때 대부분의 조회 패턴에는 가입 대리점 또는 처리 대리점에 해당하는 값이 들어오기 마련이다. 이럴 때 I_DLR_IND로 리스트 파티셔닝을 한다면 어떨까. 즉 집합의 서브 타입을 분류할 때 리스트 파티션은 매우 유용하다. 지금 예로 든 것은 단편적인 것에 불과하지만 리스트 파티셔닝의 위력은 강력하다. 특히 컴포지트 파티션에서 레인지 파티션과 함께 사용하면 전체 데이터베이스의 성능을 크게 향상시킬수 있다. 다음은 리스트 파티션을 만드는 DDL 스크립트이다.
CREATE TABLE SERVICE_CONTRACT
(I_YYYYMMDD VARCHAR2(8), I_CUSTOMER VARCHAR2(6),
I_DLR_IND VARCHAR2(2), I_DEALER VARCHAR2(6), …….)
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0)
PARTITION BY LIST (I_DLR_IND)
(PARTITION PAR_A VALUES (‘A’), PARTITION PAR_S VALUES (‘S’))
PARTITION BY LIST에 나타나는 COLUMN_LIST는 파티셔닝 컬럼으로 파티션 키에 해당하고(단 단일 컬럼만 지정할 수 있다), VALUESS LESS THAN에 나타나는 VALUE_LIST는 파티셔닝 컬럼들의 값이다. 여기에 나타낸 값에 해당하는 행들을 저장하겠다는 의미가 된다.
레인지의 장점을 그대로, 레인지-해시 컴포지트 파티셔닝
레인지-해시 컴포지트 파티셔닝은 레인지 방식을 사용해 데이터를 파티셔닝하고 각각의 파티션 내에서 해시 방식으로 서브 파트셔닝을 하는 방식이다. 서브 파티션이 독립된 세그먼트가 되는 것이 특징으로, 다음과 같은 장점이 있다.
◆ 관리와 성능 등 레인지 파티션의 장점을 그대로 수용한다.
◆ 해시 파티션의 이점인 데이터 균등 배치와 병렬화
◆ 서브 파티션에 특정 테이블스페이스를 지정할 수 있다.
◆ 서브 파티션별로 풀 스캔을 할 수 있어 스캔 범위를 줄여 성능을 향상시킨다.
레인지 파티션에서 해당 테이블이 단지 논리적인 구조이고 실제 데이터는 파티셔닝된 세그먼트에 저장됐던 것처럼 컴포지트 파티션에서도 해당 테이블과 파티셔닝된 테이블은 단지 파티셔닝을 위한 논리적인 구조일 뿐이다. 데이터는 가장 하위에 위치한 서브 파티션 영역에 저장된다. 다음은 레인지-해시 컴포지트 파티션을 생성하는 DDL 스크립트이다. PARTITION BY RANGE (I_YYYYMMDD)에 의해 레인지로 파티션을 한 후 SUBPARTITION BY HASH에 의해 서브 파티셔닝을 수행했음을 알 수 있다.
CREATE TABE TB_RANGE_HASH
(I_YYYYMMDD VARCHAR2(8), I_SERIAL NUMBER, SALE_PRICE NUMBER, ……)
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0)
PARTITION BY RANGE (I_YYYYMMDD)
SUBPARTITION BY HASH (I_SERIAL)
(PARTITION SALES_1997 VALUES LESS THAN (‘19980101’)
(SUBPARTITION SALES_1997_Q1 TABLESPACE TBS2,
SUBPARTITION SALES_1997_Q2 TABLESPACE TBS3), ……)
레인지-리스트 컴포지트 파티셔닝
레인지-리스트 컴포지트 파티셔닝은 레인지 방식을 사용해 데이터를 파티셔닝하고 각 파티션 안에서 리스트 방식을 이용해 서브 파티셔닝하는 방식이다(이때 서브 파티션은 독립된 세그먼트가 된다). 레인지-리스트 컴포지트 파티션은 레인지-해시 컴포지트 파티션과 비슷하지만 서브 파티션이 리스트 파티션이라는 점이 다르다. 실제 업무에서는 레인지-해시보다 유용한 면이 많다. 다음은 레인지-리스트 컴포지트 파티션을 생성하는 DDL 스크립트이다.
CREATE TABLE TB_RANGE_LIST (
I_YYYYMMDD VARCHAR2(8), I_AGR_IND VARCHAR2(2), I_DELAER VARCHAR2(6), …….)
TABLESPACE TBS1
STORAGE (INITIAL 2M NEXT 2M PCTINCREASE 0 MAXEXTENTS UNLIMITED)
PARTITION BY RANGE (I_YYYYMMDD)
SUBPARTITION BY LIST (I_AGR_IND)
(PARTITION PAR_1997 VALUES LESS THAN (‘19980101’)
(SUBPARTITION PAR_1997_A VALUES (‘A’), SUBPARTITION PAR_1997_A VALUES (‘S’)),
……)
파티션된 인덱스의 참뜻
‘파티션된 인덱스(partitioned index)’라고 하면 대부분의 개발자들은 로컬 인덱스를 떠올린다. 또한 파티션된 테이블에서만 쓰이는 것으로 생각한다. 그러나 이것은 명백한 오산이다. 파티션된 인덱스는 파티션된 테이블과 별개의 것으로, 단지 많은 상호 연관을 갖고 있을 뿐이다. 파티션된 인덱스는 문자 그대로 인덱스를 파티셔닝한 것으로, 해당 테이블이 파티션된 테이블이든 파티션되지 않은(non-partitioned) 테이블이든 상관없이 만들 수 있다.
예를 들면 ‘EMP’ 테이블의 크기가 상당히 크고 파티션되지 않은 일반 테이블일 경우 다음과 같은 과정을 통해 파티션된 인덱스를 만들 수 있다. 이를 ‘Global Prefixed Partitioned Index’라고 부르는데, 파티션 인덱스와 마찬가지로 대용량 데이터 환경에서 성능을 높이고 관리를 편리하게 하기 위해서다.
CREATE INDEX EMP_IDX1 ON EMP (DEPTNO)
GLOBAL
PARTITION BY RANGE (DEPTNO)
(PARTITION PAR_10 VALUES LESS THAN (‘20’) TABLESPACE TBS1,
PARTITION PAR_20 VALUES LESS THAN (‘30’) TABLESPACE TBS2,
PARTITION PAR_30 VALUES LESS THAN (‘40’) TABLESPACE TBS3,
PARTITION PAR_40 VALUES LESS THAN (‘50’) TABLESPACE TBS4,
PARTITION PAR_MAX VALUES LESS THAN (MAXVALUE) TABLESPACE TBS5)
파티션된 인덱스가 유용한 이유는, 앞서 파티션의 개념에서 설명한 것처럼 하나의 인덱스를 여러 개의 독립적인 물리 속성을 가진 세그먼트로 나누어 생성, 관리할 수 있기 때문이다. 오라클 DBMS에서 제공하는 인덱스는 글로벌/로컬 인덱스와 Prefixed/Non-Prefixed 인덱스로 분류된다.
파티션된 인덱스와 일반 인덱스 사이의 차이점은 파티션 테이블과 일반 테이블의 그것과 동일하다. 인덱스는 인덱스 컬럼과 Rowid 순으로 값이 정렬되는데, 이런 특성은 파티션 인덱스에서도 동일하다. 많은 개발자들이 파티션된 인덱스는 전체 테이블 값이 정렬되지 않는다고 생각하지 하지만 이것은 사실과 다르다. 글로벌 파티션된 인덱스의 경우 테이블에 대해 값 정렬이 보장돼 있으며, 인덱스도 파티션별로 독립적으로 관리할 수 있다. 두 가지 방식의 차이는 <그림 1>과 같다.
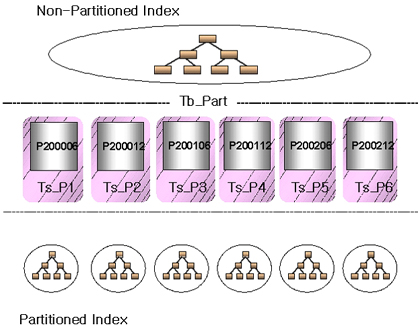 |
| <그림 1> 파티션된 인덱스와 파티션되지 않은 인덱스의 차이 |
파티션되지 않은 인덱스는 하나의 루트(root) 노드에서 리프(leaf) 노드까지 전체적인 밸런스를 유지하는 구조이고, 파티션 인덱스는 파티션 별로 독립적인 루트 노드와 리프 노드를 갖고 있음을 알 수 있다. 따라서 파티션되지 않으면 대용량 테이블에서는 글로벌 인덱스의 깊이(depth)가 매우 깊어질 수 있는 단점이 있다.
반면 파티션된 인덱스는 각 파티션별 깊이가 일반 인덱스의 깊이보다 얕고 인덱스도 파티션 별로 할 수 있어 병렬 프로세싱을 이용한 인덱스 관리에 매우 효과적이다.
그렇다면 글로벌 인덱스와 로컬 인덱스는 어떤 차이가 있는 것일까? 많은 개발자들이 파티션됐는지 여부로 판단하지만 이것은 잘못된 생각이다. 앞서 설명한 것처럼 글로벌 인덱스도 파티셔닝할 수 있으며, 이를 파티션별로 관리할 수도 있다. 글로벌 인덱스와 로컬 인덱스의 가장 큰 차이는 ‘정렬’이다. 즉 글로벌 인덱스는 테이블 전체에 대해 인덱스된 컬럼과 Rowid 순으로 정렬되고, 로컬 인덱스는 해당 파티션 내에서만 인덱스된 컬럼과 Rowid 순으로 정렬된다.
또한 로컬 인덱스는 ‘Local’이라는 말에서 알 수 있듯이 지역적인 인덱스로, 해당 테이블(base table)의 파티션 키로 파티셔닝된 인덱스다. 일반적으로 로컬 인덱스의 구성 컬럼에 반드시 파티션 키가 포함돼야 가능한 것으로 알려져 있지만 로컬 인덱스에는 파티션 키가 포함되어 있지 않아도 사용할 수 있다. 다음 예제를 보자. PACKAGE_DLR_IDX1 인덱스의 구성 컬럼에 테이블 파티션 키인 I_DLR_IND가 포함되지 않아도 검색조건에 I_DLR_IND = ‘C’라는 검색 조건이 있기 때문에 해당 파티션의 로컬 인덱스를 이용하는 것을 알 수 있다.
| select |
| *from PACKAGE_DLR |
| where i_package = ‘AAA’ and i_dlr_ind = ‘C’ |
| Operation | Object Name | PStart | PStop | | SELECT STATEMENT Hint=CHOOSE | | | | | TABLE ACCESS BY LOCAL INDEX | ROWIDPACKAGE_DLR | 3 | 3 | | INDEX RANGE SCAN | PACKAGE_DLR_IDX | 3 | 3 |
|
글로벌 인덱스는 전역적인 인덱스로, 기본적으로는 파티션되지 않은 인덱스이다. 대부분의 개발자들은 글로벌 인덱스를 파티셔닝해 사용할 생각을 하지 못하는데, 대용량 테이블에서 인덱스 관리의 효율성을 높이고 인덱스 검색 성능을 높이기 위해서는 이를 파티셔닝하는 것이 좋다. 글로벌 인덱스는 기본 테이블의 파티션 키와 무관하게 파티셔닝하는 것으로 설사 기본 테이블의 파티션 키로 글로벌 인덱스를 파티셔닝했다고 해도 로컬 인덱스처럼 동일파티셔닝(equipartitioning)된 개념이 아니므로 테이블 DDL시 전체 인덱스를 다시 생성해야 한다.
그렇다면 글로벌 파티션 인덱스의 인덱스 컬럼 값은 어떻게 전체 테이블에 대해 정렬을 보장하는 것일까. 예를 들어 5000만 건의 파티션되지 않은 EMP 테이블을 부서번호에 따라 파티셔닝했다고 가정하면 다음과 같다.
CREATE INDEX EMP_IDX1 ON EMP (DEPTNO)
GLOBAL
PARTITION BY RAGE (DEPTNO)
(PARTITION PAR_10 VALUES LESS THAN (‘20’) TABLESPACE TBS1,
PARTITION PAR_20 VALUES LESS THAN (‘30’) TABLESPACE TBS2,
PARTITION PAR_30 VALUES LESS THAN (‘40’) TABLESPACE TBS3,
PARTITION PAR_40 VALUES LESS THAN (‘50’) TABLESPACE TBS4,
PARTITION PAR_MAX VALUES LESS THAN (‘MAXVALE’) TABLESPACE TBS2,
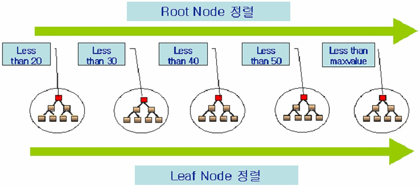 |
| <그림 2> Global Prefixed Partitioned 인덱스 |
<그림 2>는 Global Prefixed Partitioned 인덱스의 구조다. Prefixed와 Non-Prefixed는 인덱스 파티셔닝 키가 인덱스의 선두 컬럼으로 오는가 그렇지 않은가의 차이가 있다. <그림 2>에서도 ‘Prefixed’란 인덱스의 파티션 키(DEPTNO)가 인덱스 선두 컬럼(DEPTNO)이 되는 것을 알 수 있다. 글로벌 인덱스의 경우 모든 인덱스 컬럼 값이 정렬돼 있다. 각 인덱스 파티션의 루트 블럭(root block)에 들어가는 값들이 인덱스 파티션에 따라 정렬되기 때문에 자연적으로 리프 블럭(leaf block)에 들어가는 모든 값들도 정렬되는 것이다. 반면 Global Non-Prefixed 인덱스를 파티셔닝하면 레인지 파티셔닝 방식으로만 가능하다. 이것은 정렬 때문인데, 레인지 파티션은 정렬 기능을 이용해 파티셔닝 키 자체를 생성하는데 반해 다른 파티셔닝 방식은 정렬과 상관없이 수행하기 때문이다.
로컬 인덱스는 Prefixed 인덱스와 Non-Prefixed 인덱스를 모두 지원한다. 로컬 인덱스는 기본적으로 현재 테이블의 파티션 키가 인덱스의 파티션 키가 되기 때문에 인덱스 컬럼에 현재 테이블의 파티션 키가 포함되지 않아도 인덱스를 생성할 수 있다. 또한 인덱스 컬럼 값의 정렬이 전체 테이블에 대해 보장된 것도 아니기 때문에 인덱스 파티션 키가 인덱스의 선두 컬럼이 될 필요가 없다. 또한 Non-Partitioned 인덱스이든 파티션 인덱스든 상관없이 인덱스를 이용하고자 할 때는 무조건 인덱스 파티션 키를 조회해야 하는 글로벌 인덱스와 달리 로컬 인덱스는 조회 검색조건에 파티션 키가 들어올 수도 있고 들어오지 않을 수도 있다.
대용량 DB 테이블과 인덱스 전략
파티션 인덱스 전략은 파티션 테이블과 밀접하게 연관되어 수립해야 하지만 여기서는 파티션 인덱스를 위주로 이야기를 풀어본다. 먼저 인덱스 크기에 대한 논의는 기본적으로 테이블보다는 훨씬 작게 생성, 관리하는 것이 원칙이다. 따라서 중소 용량의 데이터베이스 환경에서는 파티션 인덱스의 유용성을 따질 필요가 없다. 단 중소 용량의 데이터 환경일 경우에서도 테이블이 파티셔닝돼 있다면 파티션 인덱스를 고려해야 한다. 또한 기본적으로 파티션되지 않은 인덱스(일반 인덱스) 전략을 기본으로 해 테이블이 파티셔닝 된 경우와 인덱스를 파티셔닝했을 때의 장점을 비교해 보아야 한다.
먼저 테이블 파티션 키가 항상 ‘=’로 들어오는 경우 또는 파티션 범위가 크지 않은 경우에는 로컬 인덱스가 최상이다. 인덱스 컬럼의 순서와 구성은 액세스 패스에 따라 생성하면 되지만 최대한 가볍게 생성하는 것이 좋다. 기본 테이블의 파티션 키는 반드시 포함될 필요가 없으나, 테이블이 레인지 파티션이고 한 파티션 범위 안에서 파티션 키의 분포도가 좋을 경우 이를 포함하는 것을 고려해 볼만하다. 이렇게 하면 각 파티션당 인덱스가 파티션되지 않았을 때보다 가벼워지고 데이터 마이그레이션을 할 때도 테이블 파티션과 인덱스 파티션이 동일하므로 exchange, add, drop, split 등 파티션별 관리도 용이하다.
또한 빠른 응답 시간을 요구하는 환경에서 대용량 파티션 테이블의 조회 조건에 파티션 키가 들어오지 않을 가능성이 있다면 파티션 글로벌 인덱스를 고려해 볼만하다. 이렇게 하면 파티션되지 않은 글로벌 인덱스와 달리 레인지 파티션 별로 인덱스가 가벼워지는 장점이 있고, 레인지 파티션 별로 인덱스 split와 rebuild 명령을 독립적으로 수행할 수 있다. 컬럼 분포도에 따른 파티셔닝이나 민감한(critical)한 상수 레인지에 대해서는 파티션을 독립적으로 생성해 인덱스 크기를 줄임으로써 인덱스 검색 시간을 줄일 수 있는 이점도 있다.
exchange는 파티션된 테이블의 특정 파티션과 파티션되지 않은 일반 테이블 간의 구조를 서로 바꾸는 것으로, 대용량의 파티션된 테이블을 관리하는 데 상당한 효과가 있다. <그림 2>와 같이 데이터가 없는 새로운 데이터 테이블과 데이터가 들어 있는 파티션 2를 exchange하면 파티션 2에 해당하는 디렉토리 정보가 새로운 데이터로 바뀌고 새 테이블 데이터에는 데이터가 들어간다. 이것은 실제 데이터가 이동하는 것이 아니라 데이터를 저장하는 테이블 정보만을 업데이트하는 것이다. 한 가지 주의할 점은 exchange하고자 하는 파티션과 테이블의 구조가 같아야 하고 속성들의 특성도 같아야 한다는 사실이다.
exchange의 기본적인 문법은 다음과 같다.
Alter table Tb_Partition
Exchange partition par_200306
With table Tb_Exchange
(Without validation Including indexes)
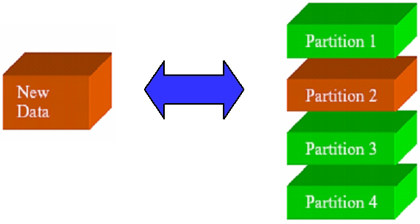 |
| <그림 3> 대용량 DB에서 exchange 작업 |
한편 파티션된 대용량 테이블에 split 함수를 실행하면 많은 시간이 걸린다. 이럴 때 exchange 기능을 이용하면 빠르고 안전하게 작업할 수 있다. <그림 4>에서 보는 것처럼 split를 해야 하는 파티션을 exchange에 의해 빈 공간으로 만든 다음 split을 하고 다시 데이터를 채우기 위해 split하는 것이다. 이렇게 하면 대용량의 데이터라도 매우 빠른 시간내에 split 작업을 수행할 수 있다.
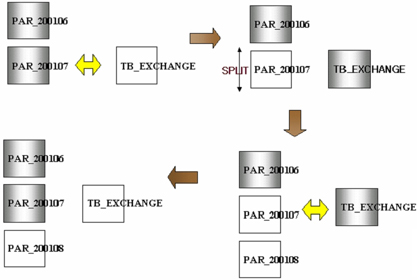 |
| <그림 4> 대용량 DB에서 split 작업 |
한편 대부분의 DBA들과 개발자들은 동일한 테이블을 생성할 때 create table ~ as select 구문을 이용한다. 대용량의 데이터일 경우 parallel 옵션을 줘 생성하기도 한다. 만약 1억 건의 테이블을 그대로 생성한다고 할 때 어떤 방법이 효과적일까. 이렇게 파티션된 대용량 테이블을 생성할 때는 exchange, program parallel 방법을 사용하는 것이 바람직하다.
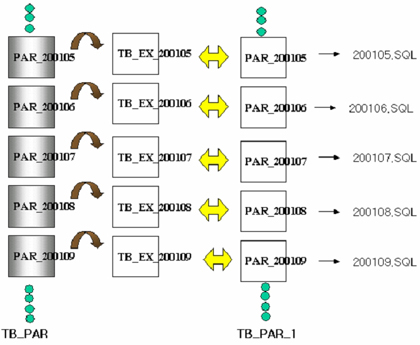 |
| <그림 5> 동일 테이블을 만들 때 |
<그림 5>는 이 과정을 도식화한 것이다. 먼저 생성할 TB_PART_1 테이블의 빈껍데기를 만든다. 대용량의 파티션된 테이블의 파티션 각각을 create table ~ as select 구문의 parallel 옵션을 이용해 각 테이블로 생성한다. 이후 미리 생성해 놓은 TB_PART_1 테이블의 파티션과 만들어 놓은 테이블들을 exchange하는 것이다. 이때 파티션별로 200105.sql, 200106.sql, 200107.sql…… 형식으로 만들어 놓고 이 프로그램들을 동시에 실행하면(program parallel) 극적인 효과를 볼 수 있다.
이번엔 데이터 마이그레이션에 대해 살펴 보자. 원격으로 데이터를 옮겨야 할 때 보통 database link를 이용한다. 네트워크를 통해 데이터를 옮기면 직렬(serial)로 데이터가 이동되므로 속도가 현저하게 떨어지기 때문이다. 따라서 소스 테이블을 파티셔닝하고 해당 파티션을 액세스하는 프로그램을 각각 띄워 병렬 프로세싱을 하게 되면 매우 빠른 속도로 데이터를 옮길 수 있다.
소스 테이블을 파티셔닝할 수 있는 상황이라면 테이블의 분포를 보고 레인지나 리스트 방식으로 파티셔닝할 수 있고, 일정한 분포가 존재하지 않는 테이블이라면 해시 파티셔닝으로 분포도를 고르게 나눈 다음 해당 파티션을 읽는 뷰를 액세스해 데이터를 옮기는 것이 좋다.
예를 들어 다음은 중대형 정도 크기인 약 2700만 건의 회원 테이블을 옮기는 DDL 스크립트다. 앞서 언급한 대로 이를 바로 database link를 이용해 처리하면 네트워크의 속도가 떨어져 엄청난 시간이 소요된다. 그러나 이것을 일반 테이블을 여러 개로 파티션을 나누어서 파티션과 병렬 처리하면 성능이 크게 향상된다. 작업 순서는 다음과 같다.
create table t_cust_hash
storage (initial 5M next 5M pctincrease 0)
partition by hash(mem_no)
(
partition par_hash_1 TABLESPACE TS_DATA,
partition par_hash_2 TABLESPACE TS_DATA,
partition par_hash_3 TABLESPACE TS_DATA,
partition par_hash_4 TABLESPACE TS_DATA,
partition par_hash_6 TABLESPACE TS_DATA,
partition par_hash_7 TABLESPACE TS_DATA,
partition par_hash_8 TABLESPACE TS_DATA,
partition par_hash_9 TABLESPACE TS_DATA,
partition par_hash_10 TABLESPACE TS_DATA,
)
nologging
as
select /*+ parallel(x 10) */ * from t_cust x
이제 다음과 같이 소스 테이블 뷰 생성한 후
create or replace view t_cust_1
as select * from t_cust_hash partition (par_hash_1);
create or replace view t_cust_2
as select * from t_cust_hash partition (par_hash_2);
create or replace view t_cust_3
as select * from t_cust_hash partition (par_hash_3)
……
다음과 같이 프로그램 패러럴(program parallel) 작업을 동시에 실행한다.
T_cust_1.sql
create table t_cust_1
storage (initial 5M next 5M pctincrease 0)
nologging
tablespace njh
as
select /*+ parallel(x 4) */ * from t_cust_1@remote x;
T_cust_2.sql
create table t_cust_2
storage (initial 5M next 5M pctincrease 0)
nologging
tablespace njh
as
select /*+ parallel(x 4) */ * from t_cust_2@remote x
이것은 단적인 예에 지나지 않는다. 활용할 수 있는 사례는 얼마든지 있을 것이다. 한편 인덱스는 전체 데이터에 대해 해당 컬럼의 값으로 정렬하기 때문에 대용량 테이블의 경우 create, rebuild 명령을 실행할 때 많은 시간이 필요하다. 이때 파티션된 인덱스를 만들면 인덱스의 생성과 관리를 더 활용적으로 할 수 있다. 다음은 파티션된 인덱스를 Unusable로 생성한 사례다(로컬/글로벌 파티션된 인덱스).
먼저 파티션 인덱스를 ‘unusable’ 옵션을 이용해 생성한다. 실제 데이터를 정렬해 만드는 것이 아니라 일종의 껍데기를 만드는 과정이다. 이제 앞서 살펴본 병렬 처리를 이용해 여러 파티션을 동시에 rebuild를 하면 대용량 데이터라도 빠른 시간에 인덱스를 생성할 수 있다.
CREATE INDEX EMP_IDX1 ON EMP (DEPTNO)
GLOBAL
PARTITION BY RANGE (DEPTNO)
(PARTITION PAR_10 VALUES LESS THAN (‘20’) TABLESPACE TBS1,
PARTITION PAR_20 VALUES LESS THAN (‘30’) TABLESPACE TBS2,
PARTITION PAR_30 VALUES LESS THAN (‘40’) TABLESPACE TBS3,
PARTITION PAR_40 VALUES LESS THAN (‘50’) TABLESPACE TBS4,
PARTITION PAR_MAX VALUES LESS THAN (MAXVALUE) TABLESPACE TBS5)
UNUSABLE;
이제 파티션별로 index1.sql, index2.sql 등을 독립적으로 병렬 실행한다.
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_10 PARALLEL 4; ---‘ index1.sql
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_20 PARALLEL 4; ---‘ index2.sql
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_30 PARALLEL 4; ---‘ index3.sql
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_40 PARALLEL 4; ---‘ index4.sql
ALTER INDEX EMP_IDX1 REBUILD PARTITION PAR_MAX PARALLEL 4; ---‘ index5.sql




