SQL 성능 관리를 위한 AWR Data의 활용
성능 개선… 어떻게 무엇을
현재는 다우기술에서 DB 관리 업무를 담당하고 있지만 얼마 전 까지만 해도 여러 기업을 대상으로 데이터베이스의 성능 문제를 분석하고 개선하는 일을 해왔습니다. 보통 10일, 짧으면 하루도 못 되는 시간 동안 분석과 개선을 해야 하는 경우가 많았습니다. 주어진 시간이 많지 않기 때문에 대상 시스템에 대한 성능 개선의 효과를 높이기 위해 시스템 전체 관점에서 문제가 되는 원인을 찾을 필요가 있었습니다.
따라서 제한된 시간 안에 시스템에 가장 큰 영향을 미치는 원인을 발견하는 것이 중요한 과제였습니다. 또한 그리고 그게 왜 중요한 것인지를 담당자에게 이해시키고 그 개선 효과에 대해 전달해 해당 문제를 개선하는 것이 시스템 전체에 어떤 영향을 미칠 것인지를 알려주는 것 또한 중요한 일이었습니다.
이런 종류의 문제는 저와 같은 입장을 가진 사람들에게도 중요하지만 일반 DB 관리자 입장에서도 중요한 문제가 됩니다. 지금까지의 경험상 문제가 무엇인지 명확해지면 대부분의 문제는 해결이 됐습니다. 그 방법이 SQL Tuning이나 Server Tuning을 통한 방법이 됐던 장비 교체를 통한 방법이 됐던 업무 요건을 개선하는 방법이 됐던 말입니다. 따라서 ‘어떻게 해결할 것인가’의 측면보다는 ‘무엇을 해결해야 하는가’가 더 중요하다고 생각합니다. 물론 ‘왜 해결해야 하는가’는 더 중요한 이유가 될 수 있겠지요.
이 글에서 별도의 도구 없이 어떻게 ‘무엇을 해결해야 하는가’를 찾을 수 있는 방법을 논해보고자 합니다. 방법은 논하기 전에 관련된 일반적 접근법을 논해보도록 하겠습니다.
시스템의 성능 문제를 발견하기 위해 여러 가지 접근법이 있을 수 있습니다. 일반적으로 많이 사용하는 방법은 SQL문 위주의 접근을 하는 것입니다. 자원 사용량, 대기량 등의 지표를 통해 접근하는 방법도 있습니다. 데이터베이스에서 작업을 하는 과정에서 여러 자원들이 개입되는데 어느 자원을 많이 사용하면 관련된 대기량이 증가하고 대기량이 증가하면 성능이 저하돼 성능 문제로서 인식하게 되는 것이지요. 문제가 되는 자원 사용량, 대기량 지표가 발견되면 해당 시점에 해당 자원을 많이 사용했던 SQL문장 또는 수행 구조를 찾아 개선하기도 합니다.
SQL문장과 자원 사용량 또는 대기량과의 관계는 SQL문장이 자원 사용량 또는 대기량의 절대값을 결정하고 또 자원 사용량 또는 대기량이 SQL문장의 성능에 영향을 미치는 관계로 볼 수 있습니다. 따라서 어느 방법을 사용하던 문제의 본질에 다가갈 수 있습니다
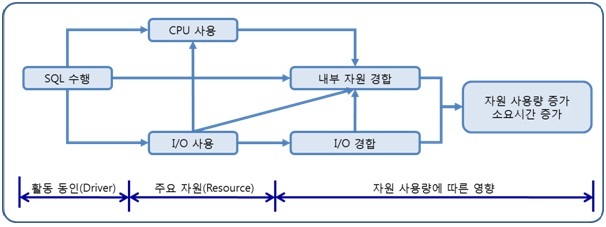
이 방법들은 개별 자원 또는 개별 SQL문장 중심의 접근이 아닌 데이터베이스 전체 시스템의 관점에서 접근하므로 Top-Down 방식의 접근이라고 합니다.
SQL 성능 개선을 위한 AWR의 활용
활동 동인으로서의 SQL 문장, 주요 자원 사용량을 알려주는 자원 사용량 또 그에 영향을 받는 대기량의 관계를 통해 SQL문장이 문제 분석의 정점에 있다고 볼 수 있습니다. 그럼 어떤 방식으로 시스템에 많은 영향을 미치는 SQL 문장을 발견할 수 있을까요 성능 관리 목적으로 출시된 여러 Tool들도 도움이 될 수 있습니다만 이 지면을 통해 소개하고자하는 내용은 ORACLE이 제공하는 AWR(Automatic Workload Repository, 이하 AWR)를 통해 문제가 되는 SQL문장을 식별하고, 자원사용량 및 대기량 지표와의 관계를 통해 해당 SQL문장의 성능 개선이 시스템에 어느 정도의 영향을 미칠 수 있는지 예측하고 관련 이해당사자들에게 해당 문제를 인지시키고 변경 작업에 대한 설득을 하기 위한 자료를 어떻게 만들지에 대한 것입니다.
AWR은 상당히 많은 데이터베이스의 성능 지표를 수집하는데요 SQL 문장은 물론 관련된 여러 자원 사용량 및 대기량 지표를 포함하고 있습니다. AWR의 정보를 추출하는 가장 일반적인 방법은 ORACLE에 제공하는 AWR Report를 활용하는 것입니다. AWR Report에는 특정 구간에서의 여러 자원 사용량과 대기량 그리고 주요 자원을 많이 사용한 SQL문장의 정보를 제공해 주기 때문에 폭넓은 분석이 가능하며 쉽게 추출해 활용할 수 있다는 장점이 있습니다.
하지만 AWR은 분석 대상 기간의 시작과 끝 시점의 변화량에 대한 평균 값을 제시해 그 과정에 대한 정보를 얻을 수 없고 SQL문에 대한 정보도 제한된 정보를 제공해 해당 SQL문제에 대한 분석을 수행하기 위해 추가적인 분석이 더 요구된다는 것이 아쉬운 점입니다.
먼저 AWR Report가 제공하는 SQL 성능 정보를 먼저 알아보기로 하겠습니다. AWR Report에서 제공하는 SQL 성능 지표는 여러 가지 자원 사용량의 관점에서 해당 자원을 많이 사용한 상위 SQL문장을 제공합니다. 대표적인 것 몇 가지를 들자면 다음과 같습니다.

더 많은 내용이 있지만 이 정도만 설명하도록 하겠습니다. SQL문장의 성능 문제를 여러 자원의 관점에서 기술하는 것은 각 관점마다 현상과 접근 방법이 다를 수 있기 때문에 여러 관점별로 접근하는 것은 중요한 의미가 있습니다. 일반적으로 최종 소요시간인 Elapsed Time을 감소시키면 문제가 해결될 수도 있지만 Elapsed Time은 앞서 설명한 그림에서와 같이 여러 가지 이유에 의해 증가할 수 있습니다. 또한 데이터베이스가 작동하는 Server의 특정 자원 예를 들면 CPU 또는 Disk가 다른 자원에 비해 조금 더 성능 문제가 있다면 Elapsed Time을 기준으로 하기 보다는 해당 자원을 기준으로 하는 것이 더 바람직하다고 볼 수 있습니다.
여러 자원 관점에서 사용량이 큰 순서대로 정렬해서 보여주는 기법을 사용하는데 이 부분은 개선 작업의 효과성과 관련됩니다. 1개의 SQL문장을 개선했을 때 하루에 1번 수행하면서 1초도 안 걸리는 것을 개선하는 것보다는 동일한 시간이 걸리더라 100만번 수행하는 것을 개선하는 것이 성능에 더 큰 영향을 미치겠죠.
사회경제 용어 중 파레토 법칙(Pareto’s law)이 있습니다. 여러 관점에서 설명되지만 20%의 구성요소가 80%의 대상 자원을 점유한다는 의미를 가지고 있습니다. 파레토 법칙을 언급하는 이유를 아시겠지요 네. 상당히 많은 데이터베이스 시스템의 성능 문제를 분석하면 성능 문제를 유발 요소의 대부분은 SQL문장에서 비롯되고(물론 Application Design 측면으로부터 문제가 발생하기도 하지만 이 글에서 이 부분은 제외하도록 하겠습니다.) 매우 적은 SQL문장이 시스템 자원 사용량을 결정하고 있습니다. 그리고 많은 경우 20%가 아닌 5%, 1% 또는 그 이하의 문장이 이런 종류의 문제를 유발합니다.
단기간에 시스템 전체의 문제를 해결하기 위해 우리가 관심을 가져야할 대상은 1% 또는 그 이하에 해당하는 SQL문장 정도입니다. 하지만 어떤 경우는 전체 시스템 자원 사용량과는 관계없이 해당 SQL 문장의 성능이 중요한 경우도 있습니다. 결산 작업과 같이 수행 빈도는 낮지만 후속작업 수행을 위해 꼭 필요하거나 이나 특정 부류의 인사가 사용하는 화면과 같은 경우가 될 수 있습니다. 이런 경우는 전체 시스템 성능 및 자원사용량의 관점에서는 큰 영향을 미치지 못합니다. 물론 업무 중요도라는 관점에서 분류를 한다면 파레토 법칙에 해당할 수 있습니다만 전체 시스템 자원 사용량 측면에서는 하위 80%에 포함되는 경우가 대부분입니다. 전체 시스템 관점에서는 중요하지 않지만 해당 업무 담당자 입장에서는 중요한 SQL문장이 존재하는 것이 일반적입니다.
이런 SQL문장을 어떻게 발견할 지 알아보겠습니다. 자원 사용량 측면의 상위 부분을 점유하는 SQL문장은 앞서 언급된 AWR Report의 각 자원 관점별 상위 SQL 목록을 통해 알 수 있습니다.
AWR에서 제공되는 SQL 상위 목록 사례를 살펴보겠습니다.
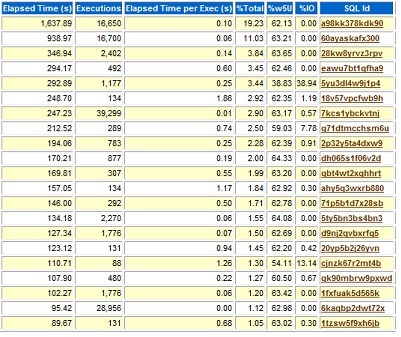
이 화면은 소요시간(Elapsed Time) 기준으로 정렬한 것으로 SQL Module과 SQL Text는 뺏습니다. 총 소요시간, 총 수행 회수, 1회 수행당 평균 소요시간, 총 DB Time 중 점유 비중, 해당 SQL 문 수행 시 CPU 사용 비중, IO Wait가 소요하는 비중이 나타나 있습니다. SQL ID를 Click하면 SQL Full Text를 확인할 수 있습니다. 자세히 살펴보면 첫번째 SQL문장의 소요시간이 꽤 큰 편이고 전체 시스템 기준에서도 비교적 많은 비중을 점유하고 있음을 알 수 있습니다. 또 다른 SQL문장들도 소요시간 기준에서 어느 정도 자원을 점유하는 것으로 나타나고 있습니다만 쉽게 눈에 들어오지는 않습니다.
AWR Report를 보조하기 위한 방법 소개
최근 들어 Big Data 분야가 많은 관심을 받고 있습니다. Big Data는 여러 관련 기술로 구성되는데 Big Data의 부상과 더불어 주목 받는 요소 기술이 데이터 시각화입니다. 분석 결과를 보다 직관적으로 이해할 수 있도록 표현하는 기법이라고 할 수 있는데요. 복잡한 시각화 기술을 사용하지 않더라도 약간의 챠트 기법을 동원하면 위와 같은 사실을 보다 인지하기 쉽도록 표현할 수 있습니다.

위에 표시된 SQL문장은 15개인데 15개의 SQL문장이 데이터베이스 소요시간의 약 61%를 점유하고 있음을 쉽게 알 수 있습니다. 시스템에서 사용되는 수 많은 SQL 문장들 중 사용자에게 불편을 초래하거나 시스템 전체 자원에 영향을 미치는 SQL문장은 많지 않다는 것을 알 수 있으며 이런 사실을 챠트로 표현할 때 텍스트로 표현할 때 보다 보다 쉽게 알 수 있습니다. 소요시간뿐 아니라 CPU 사용량, Disk 사용량 등 다른 관점에서 검토해 문제가 되는 일부 SQL문장의 성능을 개선하면 전체적으로 성능 개선 활동의 효과성을 높일 수 있습니다. 또 다른 사례를 볼까요

15개의 SQL문장이 데이터베이스 전체가 사용한 Disk Reads량의 약 80%를 점유하고 있습니다. 두 개의 SQL문장이 55%의 Disk Reads 자원을 사용하므로 SQL 2개의 Access Path를 개선하면 전체 Disk Reads량을 상당히 많이 절감할 수 있다는 것을 알 수 있습니다. 하지만 비율로 대상을 평가할 때는 한가지 주의할 점이 있습니다. 그 절대량을 함께 봐야 한다는 점입니다. 절대량이 크지 않으면 대상 SQL문장의 Access Path를 개선하더라도 대상 SQL문장뿐 아니라 전체 시스템의 자원 사용량 감소량도 미미해 큰 효과를 보기 어렵습니다. 사례에서 Disk 사용량의 25%를 점유한 SQL문장의 경우 Disk를 143824 Block(=1.1GB) 읽었습니다. Disk를 1.1GB 읽었다면 적은 량은 아니지만 하루 동안 사용한 총량으로서는 크지 않은 량입니다. 이 시점의 System 전체의 Physical Reads량의 추이를 볼까요
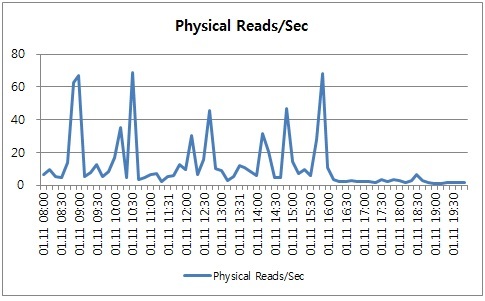
초당 사용량의 관점에서 해당 시스템의 전체 Disk Reads량은 매우 적은 편이라고 할 수 있습니다. 데이터베이스 관리자 입장에서 관리할 시스템이 많고 성능 개선 대상은 많습니다. 비율을 통한 가시성을 확보하더라도 해당 SQL문장이 사용한 절대량과 시스템 자원 사용량을 함께 고려해 중요하지 않은 것은 후 순위로 배치하는 것이 성능 개선 활동의 효과성을 높일 수 있다고 볼 수 있습니다.
성능 개선을 통해 얻을 수 있는 효과는 크게 두가지 입니다. 첫번째는 해당 SQL 또는 프로그램의 수행 소요시간 감소이고 두번째는 자원 사용량의 감소입니다. 그 중에서 주 목적은 수행 소요시간 감소라고 볼 수 있습니다. 수행 소요시간은 CPU 사용시간과 이런 저런 대기시간의 합으로 나타납니다. 수행 시간 개선을 위해 수행 시간 측면에서 가장 큰 SQL문장을 찾아 처리하는 것도 방법이지만 수행시간에 영향을 미치는 CPU 사용시간 및 대기시간이 큰 SQL문장을 찾아 성능을 개선하는 것도 방법이 될 수 있습니다.
AWR에서 제공하는 SQL 성능 관련 지표는 자원 사용량과 관련된 지표와 대기지표가 있습니다. 자원 사용량과 관련된 지표는 [표 1. AWR이 SQL 성능과 관련해 제공하는 자원 지표]에서 언급됐으므로 대기 지표를 추가적으로 알아보도록 하겠습니다.

성능 지표와 대기 지표는 앞서 [그림 1. 데이터베이스 활동 동인으로서의 SQL문장과 성능의 연관 관계]에서 살펴본 바와 같이 상호 관계를 맺고 있습니다. 그림 1의 내용을 여기서 소개한 AWR이 제공하는 성능 지표와 대기 지표간 관계를 추가해 표현해 보도록 하겠습니다.

이들의 관계를 한번 더 설명해볼까요 일반적으로 SQL Gets로 표현되는 Buffer Gets량이 높으면 CPU 사용시간이 증가하고 그에 따라 Elapsed Time이 증가합니다. SQL Reads로 표현되는 Disk Reads량이 높으면 IO Wait가 증가하고 그에 따라 SQL Elapsed Time이 증가하죠. Buffer Gets량이 높은데 Buffer Cache에 비효율적으로 접근하는 경우 내부 자원의 경합이 증가하면서 Elapsed Time이 증가할 수도 있고 RAC 환경에서 Disk 사용량이 높아 SQL Reads량이 높은 경우 CL Wait 즉, Clustered Wait가 증가해 Elapsed Time이 증가할 수도 있습니다. 자원 사용량과 관계없이 Data의 무결성 유지를 위한 Lock Wait가 발생할 경우도 Elapsed Time의 증가를 불러 일으킵니다.
예를 들어 Buffer Gets량이 높은 SQL문장의 Buffer Gets량을 감소시켜 성능 개선을 수행하는 경우가 많은데 Buffer Gets량 감소가 CPU 사용량 감소 및 관련된 I/O 경합 및 내부 자원 경합의 감소로 Elapsed Time이 감소하기 때문입니다.
모든 성능 개선 활동은 Elapsed Time을 감소시키기 위해 수행됩니다. 그런데 Elapsed Time 기준으로 SQL문장을 추출해 성능을 개선할 수도 있지만 경우에 따라 CPU의 성능이 느리거나 Disk의 성능이 느린 경우는 해당 자원을 많이 사용하거나 관련 대기 지표가 큰 SQL문장에 대해 개선할 수도 있습니다.
이런 정보들은 모두 AWR이 제공합니다. 하지만 AWR Report가 표현해 주는 정보는 일부에 그치기 때문에 SQL 성능 분석 시 아쉬운 점이 존재하기도 합니다.
관련된 비교 사례를 AWR Report와 제가 소개하는 방법으로 들어보겠습니다. 이 방법은 Excel Macro로 작성된 프로그램의 도움을 받습니다. 이 프로그램은 http://blog.daum.net/ironlegs 에 방문해서 Download 받을 수 있습니다.
SQL 성능 분석을 위한 방법론 및 사례 소개
일반적으로 CPU Time이 큰 SQL문장이 Elapsed Time도 큽니다. 그런데 다음 사례의 SQL_ID가 cgarqszyfv3rq인 SQL문장은 CPU Time과 Elapsed Time간 큰 관계가 없어 보입니다.

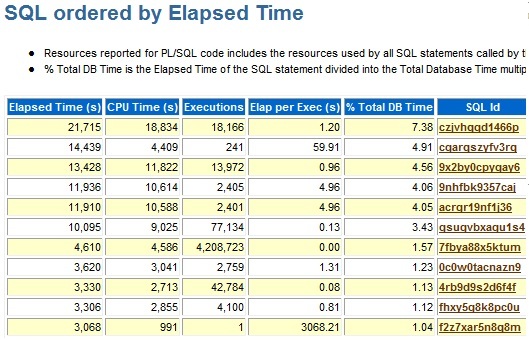
이 때의 AWR Report의 Elapsed Time과 관련된 정보는 위와 같이 표시되고 있습니다. (서두에 소개한 것과는 좀 다른 모습인데요. 서두에 소개한 내용은 11g의 AWR Report의 화면이고 위의 화면은 10g의 AWR Report의 화면입니다.) SQL_ID가 cgarqszyfv3rq인 문장의 Elapsed Time과 CPU Time이 다른 것과는 다르게 차이가 심하게 있음을 보여주고 있습니다. 이는 어떤 대기 작업이 많이 발생해 작업 수행이 지체됐음을 나타내는데요, AWR에서는 이미 이에 대한 정보를 가지고 있습니다. 아래의 내용을 보시면 총 Elapsed Time은 14,438.9초이고 CPU Time은 4,408.8초 입니다. 약 10,000초 정보도의 차이를 보여주는 데요 IO Wait가 2,815초, CLWait가 8,128초로 RAC 환경에서 Cluster Wait에 의한 대기 시간 때문에 전체 수행 시간이 증가했음을 보여주고 있습니다.

성능 개선 대상을 찾거나 성능 개선 수행 시 분석 대상 SQL문장이 성능 관점에서 어떤 특성을 가지고 있는지 미리 알고 대응하면 보다 쉽게 접근이 가능합니다.
SQL 성능 분석의 관점에서 AWR Report가 가지는 아쉬운 점이 또 존재합니다. SQL 문장만 제공한다는 점이지요. SQL 성능 개선을 위한 분석 과정에서 고려 해야 할 점은 SQL문장의 실행계획입니다. 물론 실행계획 분석을 통해 모든 성능 문제를 발견해 권고하기는 어렵지만 어떤 경우는 실행계획만 보고도 SQL문장이 가지는 문제를 확인할 수도 있습니다. 실행계획으로 분석이 되지 않을 경우 SQL문장을 실제로 수행하면서 10053/10046 Trace를 발생시킬 수도 있습니다. 이 때 필요한 것이 Bind 변수입니다. Literal SQL문이라면 Bind 변수가 필요 없지만 Literal SQL문장은 자체로서 성능 문제를 유발하는 경우가 많아 대부분 Bind 변수를 통해 수행하도록 구현하는 것이 일반적입니다. AWR은 Bind 변수도 저장해 관리하므로 과거 사용됐던 일부 Bind 변수를 추출하는 것이 가능합니다.
또 해당 SQL문장이 과거로부터 현재까지 어떤 성능 특성을 가지고 수행했는지를 알면 성능 개선 대상의 선정과정에서 도움을 받을 수 있고 해당 SQL문장의 수행 특성 또한 확인이 가능할 것입니다.
이런 정보를 또 다른 자료의 사례를 통해 보도록 하겠습니다. AWR Report의 정보 입니다. AWR Report에서는 해당 SQL문장과 대략적인 성능 정보 외에는 추가정보가 존재하지 않습니다.
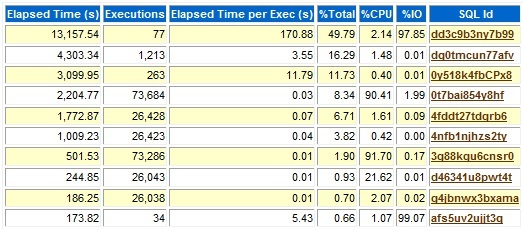
그리고 제가 소개하는 방법으로부터 나온 자료들입니다.

SQL_ID가 dd3c9b3ny7b99인 SQL문장의 성능 특성은 다음과 같이 나왔습니다.

CPU Time과 ELAPSED Time간 차이가 매우 크게 나오 있고 그 차이의 대부분이 IO Wait에 기인하고 있음을 알 수 있습니다. 이 부분은 AWR Report를 통해서도 파악이 가능하지요. 실행계획을 살펴보겠습니다

위 실행계획에는 3가지 중요 정보가 나타나고 있습니다. 파란색 밑줄 처진 부분은 해당 실행계획이 생성된 일자와 Plan Hash Value가 나오고 있습니다. 조금 연한 사각형 안의 <>에 둘러싸인 부분은 해당 Table의 통계정보 상의 자료량, 조금 진한 사각형 안의 Index 이름 다음에 나오는 숫자는 해당 Key를 통한 Data 접근 시 평균 Data Block 수, () 안의 내용은 해당 Index 구성 컬럼이며 구성 컬럼 앞의 숫자는 Index 구성 컬럼 중 조건에 의해 적용된 Index 컬럼의 개수 입니다. 붉은 동그라미가 표시하고 있는 부분을 보면 두 개의 컬럼을 가지는 Index를 Index Skip Scan을 했음을 알 수 있습니다. SQL문장을 보지 않아도 EMP_NO를 Index를 통해 적용했음을 알 수 있습니다. Index Skip Scan은 Skip 대상 컬럼의 선택성이 좋으면 즉, 가짓수가 많으면 성능 관점에서 매우 불리해집니다. 그만큼 Skip 해야 하는 경우가 많아지기 때문이지요. 해당 Index의 Key 값에 대한 평균 Data Block 수가 1이라는 값에서 알 수 있듯이 해당 Index의 가짓수는 굉장히 크다고 할 수 있습니다. 일반적으로 EMP_NO는 아주 큰 회사가 아닌 한 어느 정도 값에서 예상됩니다. 그렇다면 SER_NO 값의 가짓수가 어느 정도일지 대충 짐작이 됩니다. 그 많은 가짓수를 가지는 컬럼을 Skip Scan하는 작업을 했으니 IO Wait가 많아지는 것도 이해가 될 수 있습니다. 이를 확인하기 위해 10046 Trace를 생성하면 확신을 가질 수 있습니다. SQL 수행을 위해 Bind 변수가 필요하고 AWR에 보관된 과거 실 수행된 Bind 변수를 활용하면 비교적 높은 신뢰성의 테스트가 가능해집니다.

Bind 변수는 두 가지 Set를 제공합니다. 수집 당시 상황에 따라 두 가지 Set의 Bind 변수 값이 동일할 수도 있고 틀릴 수도 있습니다.
SQL문장의 성능 분석 시 해당 SQL문장의 과거 성능 이력까지 함께 참조하면 더 도움이 됩니다. 분석 대상 시점에만 Bind 변수를 평소와 다르게 입력해 자원을 더 많이 소요했을 수도 있고 1회 수행당 자원 사용량은 동일하지만 해당 시점에만 더 많이 수행돼 문제가 됐을 수도 있습니다. 또는 신규 추가된 서비스에서 사용된 SQL문장일 수도 있겠죠

위의 정보는 20XX년 1월 12일과 13일의 해당 SQL문장의 수행기록입니다. AWR에서 한달 치 정보를 저장하는 상황에서 이틀 치만 기록됐으니 신규 서비스에서 사용하는 SQL문장으로 이해할 수 있습니다. 사용시간과 자원 사용량, 처리량 등의 성능 지표는 기록돼 있으나 대기지표는 일부만 표시돼 있습니다. 1월 12일에는 평균 170.9초가 소요됐으며 1월 13일에는 19.8초가 소요됐습니다. 소요시간은 1/10 수준으로 감소했지만 CPU 사용시간과 1회 사용시 Buffer Gets량인 BUFF/EXEC가 크게 변화가 없는 것으로 미루어 SQL문장의 근본적인 개선이 있었다고 보기는 어떤 대기 현상에 의해 시간이 지체됐음을 알 수 있습니다. 이 내용이 위에서 살펴본 IO Wait에 의한 대기 현상이 이었습니다.
이번엔 또 다른 접근법을 알아보도록 하겠습니다. 지금까지 언급한 내용들은 개별 SQL문장보다는 전체 시스템 관점에서 문제가 되는 SQL문장에 대한 것이었습니다. 그런데 수행횟수가 많지 않아 전체 시스템 관점에서 성능 문제가 되지 않더라도 매 실행 시마다 오래 수행되는 경우가 있습니다. Background로 수행만 되는 SQL문장이면 별 문제 없지만 빠른 응답이 요구되거나, 특정 시간까지 종료돼야 하는 경우 또는 해당 SQL문장이 수행돼야 다른 중요 SQL문장이 수행될 수 있는 경우 해당 SQL문장의 수행 성능은 업무적으로 중요한 것으로 볼 수 있습니다만 이런 종류의 SQL문장은 AWR Report나 위에서 설명한 방식으로는 검색되지 않아 성능 분석가가 이런 문제를 인지하지 못할 가능성이 있습니다. 이런 경우는 특정 자원에 대한 전체 사용량 (1회 평균 사용량X수행회수)가 아닌 1회 수행 시 평균 사용량으로 접근할 필요가 있습니다. 관리가 잘 된 시스템인 경우 앞서 소개한 파이 차트에서 Top SQL 문장이 점유하는 비중이 적어지고 해당 Top SQL에 특별한 문제가 없을 수 있습니다. 하지만 전체 사용량이 아닌 1회 수행 시 평균 사용량으로 접근할 경우 또 다른 내용을 볼 수 있습니다.
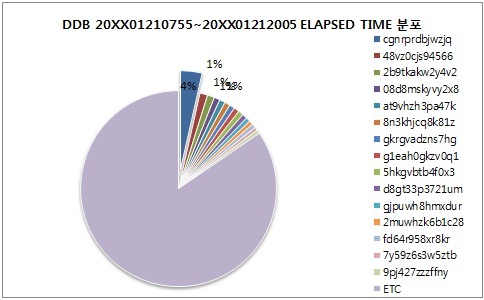
전체 시스템 관점에서 Top SQL이 점유하는 비중은 15% 정도로 작습니다. 차트가 이런식으로 출력되는 경우는 SQL 종류가 많으면서 특별히 성능 문제가 심각한 SQL문장이 존재하지 않거나 대부분의 SQL문장이 Literal SQL문장이 경우 이런 식으로 출력됩니다. 이런 경우 SQL 문장을 살펴봐도 큰 문제가 없으므로 다른 자원의 관점에서 검토하거나 바 차트로 표현된 것과 같이 1회 수행 시 자원사용량이 큰 SQL문장을 찾아보는 방법이 있습니다. 1회 수행 시 자원사용량이 큰 경우는 정상적인 프로그램 외에도 개발툴에 의한 Ad-hoc Query가 사용하는 것이 대부분인데요 SQL문장의 수행이력을 통해 위의 SQL문장은 정기적으로 수행되는 것임을 알 수 있습니다.

하루에 1~2회 정도 수행되며 1회 수행 시 약 1분 정도 소요됨을 알 수 있습니다. 만약 이 SQL문장이 사용자가 화면에서 수행해 결과를 기다리는 것이라면 해당 SQL문장의 성능 개선을 통해 시스템 자원 사용량에는 영향을 주지는 못하지만 누군가 에게는 큰 도움이 될 수도 있을 겁니다.
이런 활동을 업무 시간대를 기준으로 하거나 야간 배치 시간대를 기준으로 하거나 자원 사용량이나 Active Session 수가 높았던 시점을 중심으로 분석하는 등 관심 있는 시간대의 자원 사용량과 자원을 많이 소요한 SQL문장을 찾을 수 있습니다.


어떻게 개선할지 모른다면 넘어가시고 다른 것을 하셔도 됩니다. 성능 개선을 위해 꼭 기술적인 방법으로만 접근할 필요는 없습니다. SQL 문장 구조 변경, Hint 조정, Index 추가 등의 활동 외에도 업무 요건 변경을 통한 검색 범위 변경, 표현 정보의 제한 등의 방법으로도 성능 개선이 될 수도 있습니다. 아니면 장비를 변경해서라도 성능 개선을 할 수도 있겠죠. 또는 외부 전문가에게 의뢰하는 방법도 있습니다.
지금까지의 경험으로 성능 개선 활동은 분석 대상 구간을 변경하거나 분석 대상 자원의 관점을 변경하며 시스템 관점에서 영향이 큰 순서대로 성능 개선 활동을 수행하는 것이 바람직한 것 같습니다. 성능 개선이 잘 안되는 경우도 많이 있을 겁니다. 이런 경우 해당 SQL문장은 천천히 생각하고 다른 SQL문장을 분석하는 것이 좋은 것 같습니다. SQL문장의 성능 개선 효과와 성능 개선의 난이도는 상관관계가 없습니다. 성능 개선 효과가 큰 경우는 상대적으로 난이도가 쉽고 성능 개선 효과가 작은 경우는 상대적으로 난이도가 어려운 경우가 많습니다. 분석을 수행하며 SQL문장의 자원 사용과 대기량 간 상관 관계분석을 해보는 것도 흥미로운 일이 될 수 있을 겁니다.
정리해 보겠습니다. ‘소득 있는 곳에 세금 있다’는 말이 있죠 마찬가지로 데이터베이스 운영과 관련해 ‘자원 사용량 있는 곳에 대기량이 있다’는 말도 통용됩니다. 그리고 자원을 사용하는 주된 주체가 SQL문장이므로 SQL문장의 성능 개선을 통해 전체 자원 사용량의 감소 및 대기량의 감소 그리고 그를 통한 해당 업무 처리시간의 개선을 이룰 수 있습니다.
성능 개선 활동 자체가 불가능할 정도로 어려운 사례는 많지 않습니다. 가능한 수준에서 점진적으로 SQL 수행 성능을 개선하고 개선이 어려운 사례는 좀 더 많은 시간을 가지고 생각하고 다양한 방법으로 시험해 보면 좋은 효과를 볼 수 있으리라고 생각합니다.
'ORACLE > 튜닝' 카테고리의 다른 글
| 안정적인 운영을 위한 실행계획 제어(3) (4) | 2023.12.01 |
|---|---|
| 오라클 업그레이드 SQL 튜닝 대상 추출 (0) | 2023.12.01 |
| 오라클 19c 하드파싱 쿼리 플랜 변경 의심시 조치방법 (0) | 2022.11.04 |
| 대기 이벤트 및 잠재적 원인 (참조용) (0) | 2021.01.19 |
| AWR snap 생성 및 통계분석 Report 생성 (0) | 2021.01.18 |