병렬 처리에 관한 기타 상식
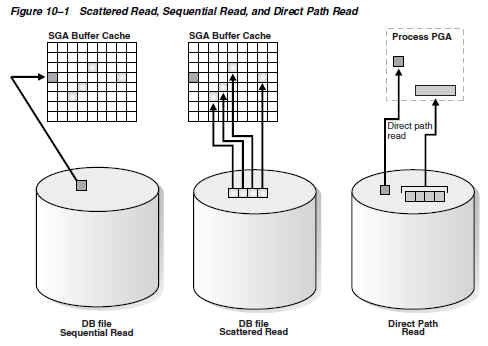
- 버퍼 캐시 히트율이 낮은 대용량 데이터를 건건이 버퍼 캐시를 거쳐 읽는다면 오히려 성능이 나빠지게 마련이다.
- 오라클은 병렬 방식 + Full Scan 할 때는 버퍼 캐시를 거치지 않고 곧바로 PGA영역으로 읽어 들이는Direct Path Read 방식을 사용한다.
- 그러나 버퍼캐시에 충분히 적재될 크기의 중소형 테이블을 병렬쿼리로 읽을 때 오히려 성능이 나빠지는 경우가 있는데, 버퍼경합이 없는 한 Disk I/O가 메모리 I/O보다 빠를 수 없기 때문이다. 게다가 Direct Path Read를 하려면 메모리와 디스크간 동기화를 맞추기 위해서 체크포인트가 먼저 수행해야 하기 때문이다.
(2) 병렬 DML
- 병렬처리를 가능하게 하려면 쿼리, DML, DDL시 다음과 같은 선처리가 필요하다.
alter session enable parallel query; -- (default)
alter session enable parallel dml;
alter session enable parallel ddl; -- (default)
- parallel query와 parallel ddl은 기본적으로 활성화 되어 있지만 parallel dml은 명시적으로 활성화 해주어야 한다.
- 주의할 점
병렬 DML을 수행 할 때 Exclusive 모드 테이블 lock이 걸린다는 사실이며, 다른 트랜잭션이 DML을 수행하지 못하므로 운영환경을 고려하여 사용해야 함.
실험 (실행계획 ch07_03.hwp 파일 참조) create table t partition by range(no) ( partition p1 values less than(25000) , partition p2 values less than(50000) , partition p3 values less than(75000) , partition p4 values less than(maxvalue) ) as select rownum no, lpad(rownum, 10, '0') no2 from dual connect by level <= 100000;
SQL> explain plan for 2 update /*+ parallel(t 4) */ t set no2 = lpad(no,5,'0'); --------------------------------------------------------------------------------------- | Id | Operation | Name | Pstart| Pstop | TQ |IN-OUT| PQ Distrib | --------------------------------------------------------------------------------------- | 0 | UPDATE STATEMENT | | | | | | | | 1 | UPDATE | T | | | | | | | 2 | PX COORDINATOR | | | | | | | | 3 | PX SEND QC (RANDOM)| :TQ10000 | | | Q1,00 | P->S | QC (RAND) | | 4 | PX BLOCK ITERATOR | | 1 | 4 | Q1,00 | PCWC | | | 5 | TABLE ACCESS FULL| T | 1 | 4 | Q1,00 | PCWP | | ---------------------------------------------------------------------------------------
SQL> alter session enable parallel dml; 세션이 변경되었습니다. SQL> explain plan for 2 update /*+ parallel(t 4) */ t set no2 = lpad(no,5,'0'); --------------------------------------------------------------------------------------- | Id | Operation | Name | Pstart| Pstop | TQ |IN-OUT| PQ Distrib | --------------------------------------------------------------------------------------- | 0 | UPDATE STATEMENT | | | | | | | | 1 | PX COORDINATOR | | | | | | | | 2 | PX SEND QC (RANDOM) | :TQ10000 | | | Q1,00 | P->S | QC (RAND) | | 3 | UPDATE | T | | | Q1,00 | PCWP | | | 4 | PX BLOCK ITERATOR | | 1 | 4 | Q1,00 | PCWC | | | 5 | TABLE ACCESS FULL| T | 1 | 4 | Q1,00 | PCWP | | --------------------------------------------------------------------------------------- |
- 첫 번째 SQL문은 병렬서버가 테이블을 읽고 갱신할 주소만 QC에 전달하고 update는 QC가 실행한다. 두 번째 SQL 문은 병렬서버가 update를 실행하고 갱신한 건수만 QC에 전달한다. - 오라클 9iR1까지는 한 세그먼트를 두 개 이상의 프로세스가 동시에 갱신할 수 없었다. 따라서 파티션되지 않은 테이블이라면 병렬로 갱신할 수 없었고, 파티션 테이블일 때라도 병렬도를 파티션 개수 이하로만 지정할 수 있었다. - 오라클 9iR2부터는 블록기반 Granule로 바뀌었다. |
(3) 병렬 인덱스 스캔
- Index Fast Full Scan이 아닌 한 인덱스는 기본적으로 병렬로 스캔 할 수 없다.
- 파티션된 인덱스일 때 병렬 스캔이 가능하며 파티션 기반 Granule이므로 병렬도는 파티션개수 이하로만 지정가능 함.
(4) 병렬 NL조인
- 병렬조인은 항상 Table Full Scan을 이용한 해쉬조인 또는 소트머지 조인으로 처리된다고 생각하기 쉽다.
하지만 인덱스 스캔을 기반으로한 병렬 NL조인도 가능
실험 (실행계획 ch07_04.hwp 파일 참조) create table emp partition by range(sal) ( partition p1 values less than(1000) , partition p2 values less than(2000) , partition p3 values less than(3000) , partition p4 values less than(MAXVALUE) ) as select * from scott.emp ; create index emp_sal_idx on emp(sal) local;
create table dept as select * from scott.dept; alter table dept add constraint dept_pk primary key(deptno);
SQL> select /*+ ordered use_nl(d) full(e) parallel(e 2) */ * 2 from emp e, dept d 3 where d.deptno = d.deptno and e.sal >= 1000;
--------------------------------------------------------------------------------------- | Id | Operation | Name | Pstart| Pstop | TQ |IN-OUT| PQ Distrib | --------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | | | | | 1 | PX COORDINATOR | | | | | | | | 2 | PX SEND QC (RANDOM) | :TQ10000 | | | Q1,00 | P->S | QC (RAND) | | 3 | NESTED LOOPS | | | | Q1,00 | PCWP | | | 4 | PX BLOCK ITERATOR | | 2 | 4 | Q1,00 | PCWC | | |* 5 | TABLE ACCESS FULL| EMP1 | 2 | 4 | Q1,00 | PCWP | | | 6 | TABLE ACCESS FULL | DEPT | | | Q1,00 | PCWP | | ---------------------------------------------------------------------------------------
|
- Parallel Full Scan은 블록 기반 Granule이 사용되므로 병렬도는 파티션 개수보다 더 클 수 있다. 단 병렬도를 너무 크게 잡으면 아무 일도 안 하는 노는 프로세스가 생길 수 있으므로 주의해야 한다. |
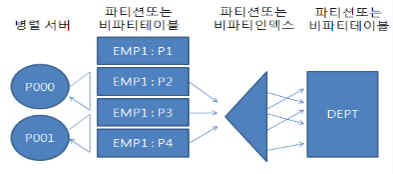
■ 병렬 인덱스 스캔으로 드라이빙하는 경우
- 파티션된 인덱스부터 드라이빙하여 병렬 NL조인을 수행
SQL> select /*+ ordered use_nl(d) index(e emp_sal_idx) 2 parallel_index(e emp_sal_idx 3) */ * 3 from emp1 e, dept d 4 where d.deptno = d.deptno and e.sal >= 1000;
-------------------------------------------------------------------------------------- | Id | Operation | Name | Pstart| Pstop | TQ | -------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | | | 1 | PX COORDINATOR | | | | | | 2 | PX SEND QC (RANDOM) | :TQ10000 | | | Q1,00 | | 3 | NESTED LOOPS | | | | Q1,00 | | 4 | PX PARTITION RANGE ITERATOR | | 2 | 4 | Q1,00 | | 5 | TABLE ACCESS BY LOCAL INDEX ROWID| EMP1 | 2 | 4 | Q1,00 | |* 6 | INDEX RANGE SCAN | EMP_SAL_IDX | 2 | 4 | Q1,00 | | 7 | TABLE ACCESS FULL | DEPT | | | Q1,00 | --------------------------------------------------------------------------------------
|
- 인덱스를 드라이빙으로 병렬처리하려면 드라이빙 인덱스가 반드시 파티션인덱스여야 한다. 드라이빙 테이블(emp)과 dept 테이블은 파티션과 상관없다. - 인덱스를 드라이빙한 병렬 NL조인에는 파티션 기반 Granule이 사용되므로 병렬도가 파티션 개수를 초과할 수 없다. - 여기서는 세 개 파티션만 액세스하므로 병렬도를 3 이상 줄 수 없다. 만약 병렬도를 2로 지정한다면 각각 하나씩 처리하다가 먼저 일을 마친 프로세스가 나머지 하나를 더 처리한다. |
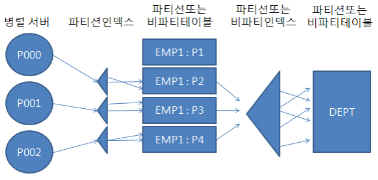
■ 병렬 NL 조인의 효용성
(사례) - 아래 조건들을 만족할 때 효율적이다.
- outer와 inner 테이블 모두 대용량이다.(어느 한쪽이 작으면 병렬 해시조인 사용) - outer 테이블에 사용된 특정 조건의 선택도가 낮은데 그 컬럼의 인덱스가 없다. - inner 쪽 조인 컬럼에 인덱스가 있다 - 수행빈도가 낮다(높으면 인덱스를 만들어 주었을 것이다) |
(5) 병렬 쿼리와 스칼라 서브쿼리
- QC의 트레이스는 user_dump_dest에 생성되고, 병렬서버의 트레이스는 background_dump_dest에 생성된다.
- 병렬처리 시 Trace 결과를 보고 스칼라 서브쿼리의 주체가 어떤 프로세스인지 알 수 있다.
- QC에 스칼라 서브쿼리 수행 통계가 나타나지 않는 경우 병렬서버 프로세스가 스칼라 서브쿼리를 수행 것임을 알 수 있고, 병렬서버 프로세스들이 order by를 위한 정렬처리를 함과 동시에 스칼라 서브쿼리를 하면서 sort area(temp)에 중간 결과집합을 담는 것을 알 수 있다.
- 병렬쿼리는 대부분 Full Table Scan을 하는데 중간에 Random액세스 위주의 스칼라 서브쿼리까지 수행한다면 수행 속도를 크게 떨어뜨린다.
- 병렬쿼리에서는 스칼라 서브쿼리를 일반 조인문장으로 변경하여 Full Scan + Parallel 방식으로 처리하는 것이 매우 중요한 튜닝기법 중 하나가 될 수 있다.
(6) 병렬쿼리와 사용자 정의 함수
- 함수에 parallel_enable 키워드를 사용하든 안하든 병렬 수행이 가능하다.
create or replace function getDname(p_deptno number) return varchar2 parallel_enable is l_dname dept.dname%type; begin select dname into l_dname from dept where deptno = p_deptno; return l_dname; end; /
select /*+ parallel(emp 2) */ empno, ename, job, sal, getDname(deptno) from emp; |
- getName() 함수가 세션 변수를 사용하지 않았으므로 parallel_enable에 관계없이 병렬수행이 가능하다. |
■ parallel_enable 키워드의 역할
- SQL 수행 결과는 병렬로 수행 되는지 여부와 관계없이 항상 일관된 결과를 반환해야 한다.
- 세션변수를 참조하는 함수는 병렬로 실행했을 때
- 패키지 변수는 세션 레벨에서만 유효하며 다른 세션과 값을 공유하지 못한다. 패키지변수를 가진 함수는 병렬 호출시 결과가 다를 수 있다. 일관성이 보장되지 않기 때문에 오라클은 병렬 수행을 거부한다. 그럼에도 불구하고 사용자가 병렬 수행을 원할 때 사용하는 키워드가 parallel_enable이다.
- 즉, 직렬과 비교해 병렬처리 시 수행결과가 달라질 수 있음에도 parallel_enable을 선언하면 오라클은 사용자의 지시에 따라 함수를 병렬로 실행할 수 있도록 허용하며 결과에 대한 책임은 사용자의 몫이라는 의미이다.
(7) 병렬쿼리와 Rownum
- SQL에 rownum을 포함하면 쿼리문을 병렬로 실행하는 데에 제약을 받게 되므로 주의해야 함.
SQL> select /*+ parallel(t1 24) */ no, no2 2 from t1 3 order by no2;
---------------------------------------------------------------- | Id | Operation | Name |IN-OUT| PQ Distrib | ---------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | | 1 | PX COORDINATOR | | | | | 2 | PX SEND QC (ORDER) | :TQ10001 | P->S | QC (ORDER) | | 3 | SORT ORDER BY | | PCWP | | | 4 | PX RECEIVE | | PCWP | | | 5 | PX SEND RANGE | :TQ10000 | P->P | RANGE | | 6 | PX BLOCK ITERATOR | | PCWC | | | 7 | TABLE ACCESS FULL| T1 | PCWP | | ----------------------------------------------------------------
SQL> select /*+ parallel(t1 24) */ no, no2, rownum 2 from t1 3 order by no2;
--------------------------------------------------------------- | Id | Operation | Name |IN-OUT| PQ Distrib | --------------------------------------------------------------- | 0 | SELECT STATEMENT | | | | | 1 | SORT ORDER BY | | | | | 2 | COUNT | | | | | 3 | PX COORDINATOR | | | | | 4 | PX SEND QC (RANDOM)| :TQ10000 | P->S | QC (RAND) | | 5 | PX BLOCK ITERATOR | | PCWC | | | 6 | TABLE ACCESS FULL| T1 | PCWP | | ---------------------------------------------------------------
|
- 각 프로시져가 P->P로 동작하여 정렬부담을 나누어가져야 함에도 불구하고 QC가 정렬을 전담하는 상황이 발생함 |
- 병렬 DML 문장에도 rownum을 사용하는 순간 병렬처리에 제약을 받는다.
alter session enable parallel dml;
explain plan for update /*+ parallel(t 4) */ t set no2 = lpad(rownum, 5, '0');
(실행계획 ch07_06.hwp 파일 참조) |
(8) 병렬쿼리 시 주의사항
■ 병렬처리가 바람직한 경우
- 동시 사용자 수가 적은 애플리케이션 환경에서(야간 배치, DW, OLAP) 직렬로 처리할 때 보다 성능 개선효과가 확실할 때.
- OLTP성 시스템 환경이더라도 작업을 빨리 완료함으로써 직렬로 처리할 때보다 오히려 전체적인 시스템 리소스 사용률을 감소시킬 수 있을 때(수행 빈도가 낮을 때), 데이터 마이그레이션 등.
■ 병렬쿼리와 관계된 주의사항
- workarea_size_policy를 manual로 설정한다면, 사용자가 지정한 sort_area_size가 모든 병렬서버에 적용되므로 적절한 sort_area_size를 설정하지 않은 경우 OS레벨에서 과도한 페이징이 발생하고 심할 경우 시스템이 마비될 수 있다.
- 병렬도를 지정하지 않으면 (cpu_count * parallel_threads_per_cpu) 만큼의 병렬 프로세스가 할당되어 의도하지 않은 수의 프로세스가 작동하게 된다. adaptive multiuser 기능을 사용하는 경우가 아니면 반드시 병렬도를 지정하자.
- 실행계획에 P->P가 나타날 때는 지정한 병렬도의 두 배수만큼 병렬 프로세스가 필요하다는 것이다.
- 쿼리 블록마다 병렬도를 다르게 지정하면 여러가지 우선순위와 규칙에 따라 최종병렬도가 결정되어 사용된다. 복잡하니 결국 쿼리 작성 시 병렬도를 모두 같게 지정하는 것이 바람직하다.
- parallel 힌트를 사용할 때는 반드시 Full 힌트도 함께 사용하는 것이 바람직하다. 간혹 옵티마이져에 의해 index 스캔이 선택된 경우 parallel 이 무시되는 경우가 발생하기 때문이다.
- parallel_index 힌트를 사용할 때는 반드시 index 또는 index_ffs 힌트도 함께 사용하는 것이 바람직하다. 옵티마이져에 의해 full table scan 스캔이 선택된 경우 parallel_index 힌트가 무시되는 경우가 발생하기 때문이다.
- 병렬 DML 수행 시 Exclusive 모드로 테이블 lock이 걸리므로 업무 트랜젝션이 발생하는 주간에는 삼가한다.
- 테이블이나 인덱스를 빠르게 생성하려고 parallel 옵션을 사용했다면 작업을 완료하자마자 noparallel로 돌려놓는 것을 잊지 말자.
- 부분범위 처리 방식으로 조회하면서 병렬 쿼리를 사용한 경우 필요한 만큼의 fetch 이후 곧바로 커서를 닫아줘야 한다. (Orange, Toad같은 툴의 경우 리소스를 해제하지 못하고 대기 상태에 있는 경우가 있으므로 select * from dual 로 새로운 쿼리를 수행하여 이전 커서를 닫아 주는 방식을 취할 수 있다.)
- 오라클 고도화 원리와 해법 2 (bysql.net 2011년 1차 스터디)
- 작성자: 박우창 (balto)
- 최초작성일: 2011년 6월 29일
- 본문서는 bysql.net 스터디 결과입니다 .본 문서를 인용하실때는 출처를 밝혀주세요. http://www.bysql.net
- 문서의 잘못된 점이나 질문사항은 본 문서에 댓글로 남겨주세요. ^^