Oracle 12C RAC DB 운영 매뉴얼
http://haisins.synology.me/wordpress/?p=3854
- Oracle 12c R1 RAC (Real Application Cluster)
- Oracle RAC에서는 Oracle Database (데이터를 실제로 보유하고 있는 Storage의 물리적 구조 즉, 데이터 파일들에서 Oracle Instance (데이터 접근 지원을 위해 서버 상에서 실행되는 프로세스 및 메모리 구조)를 분리할 수 있다.
- 클러스터 데이터베이스는 여러 개의 인스턴스가 접근할 수 있는 단일 데이터베이스이다. 각 인스턴스는 클러스터내의 별도의 서버에서 실행된다. 추가 자원이 필요한 경우, 시스템 중단 없이 클러스터에 노드 및 인스턴스를 손쉽게 추가할 수 있다. 새로운 인스턴스가 시작되면, 애플리케이션이나 애플리케이션 서버를 변경하지 않고도 서비스를 사용하는 애플리케이션이 이를 즉시 활용할 수 있다.
- Oracle RAC는 Oracle Database의 확장 기능이기 때문에 Oracle Database 12c의 관리 용이성, 안정성 및 보안성을 활용할 수 있다.
- Oracle 12c RAC Architecture

- 네트워크 구성정보
| Hostname | Public IP | Private IP | Virtual IP | SCAN IP |
| XXXDB01 | 172.30.xxx.xxx | 11.0.0.1 | 172.30.xxx.xxx | 172.30.xxx.xxx |
| XXXDB02 | 172.30.xxx.xxx | 11.0.0.2 | 172.30.xxx.xxx |
-
Oracle Grid Infrastructure Process 구조
- Cluster Synchronization Services (CSS)
- Cluster Synchronization Services (CSS)

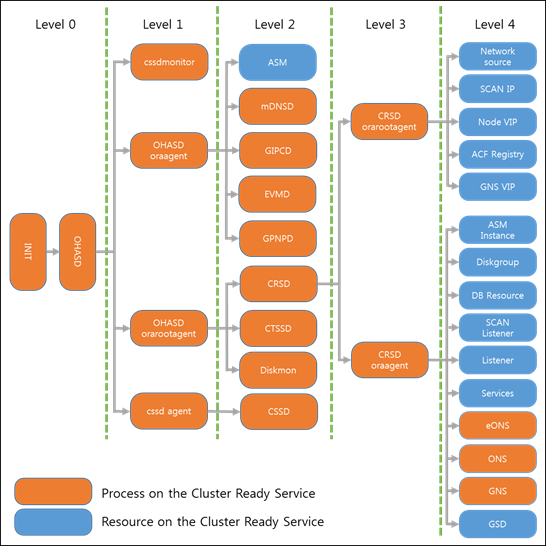
- Cluster에 어떤 node가 추가/제거 되었는지 모니터링 및 정보관리
- Heartbeat 메커니즘을 이용 (interconnect를 통한 Network Heartbeat)
- 각 멤버 node 들에게 node membership 정보 전달
- Vendor clusterware 사용시 직접 통신하면서 node membership 정보 관리
- Css 프로세스 비정상 종료 시 node reboot
- Cluster Ready Services (CRS)
- Database, Instance, Service, Listener, VIP, Application 등 모든 cluster 리소스들을 OCR에 등록되어 있는 리소스 정보에 기반하여 관리
- 리소스 모니터링 중 장애발생시 해당 리소스 start, stop, failover 조치
- cluster 리소스 등록/제거, 모니터링, 시동/중지 관련 명령어 인터페이스를 제공
- crs 프로세스 종료 시, init process에 의해 자동으로 재 기동
- Event Manager
- evmd.bin 프로세스
- grid user로 동작
- crs가 발생시키는 이벤트들을 전파
- Log 파일에 이벤트를 기록하는 역할 (evmlogger)
- Racgimon이 전달하는 메시지에 따라 racgevt 프로세스 fork
- Fail시, 자동 재 기동
- Process Monitor Daemon(OPROCD)
- IO fencing 기능 제공을 위한 Oracle 솔루션
- Vendor clusterware를 사용하는 경우, 동작 하지 않음
- Global Service Daemon(GSD)
- 9i 이전의 클라이언트가 11g CRS에 접속하여 각 종 관리업무를 수행할 수 있도록 돕는 프로세스
- 11g에서는 backward compatibility를 위해서만 존재할 뿐 특별한 역할 없음
- Virtual IP
- IP failover를 위해 Oracle CRS가 제공
- Public network interface에 VIP를 할당
- Network interface에 오류가 발생하면 CRS가 fail된 VIP의 address를 살아있는 node로 failover
- Single Client Access Name(SCAN)
- 11gR2 RAC부터 소개된 기능으로 Cluster로 구성되어 운영중인 Oracle Database 에 접근하는 모든 Client에서 SCAN으로 접속할 수 있다.
- SCAN으로 접속 시 자동으로 Server Side Load Balancing을 수행한다. (Default로 Remote Listener에 SCAN이 등록됨)
- SCAN은 Grid 설치 시 반드시 구성해야 하며, GNS을 사용하지 않는다면, SCAN NAME을 아래와 같이 DNS상에 등록해줘야 한다.
- 기본적으로 3개의 Public IP를 동일한 이름으로 등록해줘야 하며, Public과 SCAN 의 subset은 동일하여야 한다. (최소 1개의 IP등록)
-
Oracle Grid Infrastructure 관련 파일
- Oracle Cluster Registry(OCR)
- Oracle Cluster Registry(OCR)
- Cluster 리소스들에 대한 정보 저장소
- 반드시 shared disk상에 위치
- Multiplexing 가능 (multiplexing 권장)
- Enterprise Manager / Server Control Utility (SRVCTL) / Database Configuration Assistant (DBCA)을 통해서 수정 가능
- Voting Disk
- Cluster membership 관리를 위해 css 데몬이 이용
- Cluster member들의 health check
- Split brain 상태에서 node의 상태를 판단하기 위한 second heartbeat 역할
- 반드시 shared disk상에 위치
- Multiplexing 가능 (multiplexing 권장)
-
Oracle RAC 기동(Startup), 정지(Shutdown)
-
Clusterware 기동과 정지
- Oracle Clusterware 기동
- Oracle Clusterware 기동
-
- CRSCTL 유틸리티는 Oracle Clusterware를 관리한다.
- 다음의 명령어로 OHASD process가 기동되면서 Oracle Clusterware 의해 관리되는 프로세스와 리소스를 시작할 수 있다.
- 각 node에서 root 계정으로 수행하여 Cluster 리소스를 기동한다.
| # cd /grid/12.1.0.2/bin # ./crsctl start crs CRS-4123: Oracle High Availability Services has been started. |
- oracle 계정으로 아래의 명령 중 선택하여 수행하여 DB instance를 기동한다.
| # su – oracle $ srvctl start database -database -d XXXDB — 모든 node의 instance 기동 $ srvctl start instance -d XXXDB -i XXXDB1 — XXXDB1 instance만 기동 |
- Oracle Clusterware 정지
- 다음 명령어로 Oracle Clusterware 의해 관리되는 모든 프로세스와 리소스를 정지한다.
- oracle 계정으로 아래의 명령 중 선택하여 수행하여 DB instance를 정지한다.
| # su – oracle $ srvctl stop database -database -d XXXDB — 모든 node의 instance 정지 $ srvctl stop instance -d XXXDB -i XXXDB1 — XXXDB1 instance만 정지 |
- 각 node에서 root 계정으로 수행하여 Cluster 리소스를 정지한다.
| # cd /grid/12.1.0.2/bin # ./crsctl stop crs CRS-2791: Starting shutdown of Oracle High Availability Services-managed resources on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.crsd’ on ‘XXXDB01’ CRS-2790: Starting shutdown of Cluster Ready Services-managed resources on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.DG_CRS.dg’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.DG_DATA.dg’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.DG_ARCH.dg’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.LISTENER.lsnr’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.LISTENER_SCAN1.lsnr’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.oc4j’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.cvu’ on ‘XXXDB01’ CRS-2677: Stop of ‘ora.cvu’ on ‘XXXDB01’ succeeded CRS-2672: Attempting to start ‘ora.cvu’ on ‘ktms1’ CRS-2677: Stop of ‘ora.LISTENER.lsnr’ on ‘XXXDB01’ succeeded CRS-2673: Attempting to stop ‘ora.XXXDB01.vip’ on ‘XXXDB01’ CRS-2677: Stop of ‘ora.LISTENER_SCAN1.lsnr’ on ‘XXXDB01’ succeeded CRS-2673: Attempting to stop ‘ora.scan1.vip’ on ‘XXXDB01’ CRS-2677: Stop of ‘ora.DG_CRS.dg’ on ‘XXXDB01’ succeeded CRS-2677: Stop of ‘ora.DG_DATA.dg’ on ‘XXXDB01’ succeeded CRS-2677: Stop of ‘ora.DG_ARCH.dg’ on ‘XXXDB01’ succeeded CRS-2673: Attempting to stop ‘ora.DG_CRS.dg’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.DG_DATA.dg’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.DG_ARCH.dg’ on ‘XXXDB01’ CRS-2676: Start of ‘ora.cvu’ on ‘ktms1’ succeeded CRS-2677: Stop of ‘ora.DG_CRS.dg’ on ‘XXXDB01’ succeeded CRS-2677: Stop of ‘ora.DG_DATA.dg’ on ‘XXXDB01’ succeeded CRS-2677: Stop of ‘ora.DG_ARCH.dg’ on ‘XXXDB01’ succeeded CRS-2673: Attempting to stop ‘ora.asm’ on ‘XXXDB01’ CRS-2677: Stop of ‘ora.asm’ on ‘XXXDB01’ succeeded CRS-2677: Stop of ‘ora.scan1.vip’ on ‘XXXDB01’ succeeded CRS-2672: Attempting to start ‘ora.scan1.vip’ on ‘ktms1’ CRS-2677: Stop of ‘ora.XXXDB01.vip’ on ‘XXXDB01’ succeeded CRS-2672: Attempting to start ‘ora.XXXDB01.vip’ on ‘ktms1’ CRS-2677: Stop of ‘ora.oc4j’ on ‘XXXDB01’ succeeded CRS-2672: Attempting to start ‘ora.oc4j’ on ‘ktms1’ CRS-2676: Start of ‘ora.scan1.vip’ on ‘ktms1’ succeeded CRS-2672: Attempting to start ‘ora.LISTENER_SCAN1.lsnr’ on ‘ktms1’ CRS-2676: Start of ‘ora.XXXDB01.vip’ on ‘ktms1’ succeeded CRS-2676: Start of ‘ora.LISTENER_SCAN1.lsnr’ on ‘ktms1’ succeeded CRS-2676: Start of ‘ora.oc4j’ on ‘ktms1’ succeeded CRS-2673: Attempting to stop ‘ora.ons’ on ‘XXXDB01’ CRS-2677: Stop of ‘ora.ons’ on ‘XXXDB01’ succeeded CRS-2673: Attempting to stop ‘ora.net1.network’ on ‘XXXDB01’ CRS-2677: Stop of ‘ora.net1.network’ on ‘XXXDB01’ succeeded CRS-2792: Shutdown of Cluster Ready Services-managed resources on ‘XXXDB01’ has completed CRS-2677: Stop of ‘ora.crsd’ on ‘XXXDB01’ succeeded CRS-2673: Attempting to stop ‘ora.crf’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.ctssd’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.evmd’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.storage’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.gpnpd’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.drivers.acfs’ on ‘XXXDB01’ CRS-2673: Attempting to stop ‘ora.mdnsd’ on ‘XXXDB01’ CRS-2677: Stop of ‘ora.drivers.acfs’ on ‘XXXDB01’ succeeded CRS-2677: Stop of ‘ora.storage’ on ‘XXXDB01’ succeeded CRS-2673: Attempting to stop ‘ora.asm’ on ‘XXXDB01’ CRS-2677: Stop of ‘ora.crf’ on ‘XXXDB01’ succeeded CRS-2677: Stop of ‘ora.ctssd’ on ‘XXXDB01’ succeeded CRS-2677: Stop of ‘ora.mdnsd’ on ‘XXXDB01’ succeeded CRS-2677: Stop of ‘ora.gpnpd’ on ‘XXXDB01’ succeeded CRS-2677: Stop of ‘ora.evmd’ on ‘XXXDB01’ succeeded CRS-2677: Stop of ‘ora.asm’ on ‘XXXDB01’ succeeded CRS-2673: Attempting to stop ‘ora.cluster_interconnect.haip’ on ‘XXXDB01’ CRS-2677: Stop of ‘ora.cluster_interconnect.haip’ on ‘XXXDB01’ succeeded CRS-2673: Attempting to stop ‘ora.cssd’ on ‘XXXDB01’ CRS-2677: Stop of ‘ora.cssd’ on ‘XXXDB01’ succeeded CRS-2673: Attempting to stop ‘ora.gipcd’ on ‘XXXDB01’ CRS-2677: Stop of ‘ora.gipcd’ on ‘XXXDB01’ succeeded CRS-2793: Shutdown of Oracle High Availability Services-managed resources on ‘XXXDB01’ has completed CRS-4133: Oracle High Availability Services has been stopped. |
- Oracle Clusterware 상태 확인
- 전체 노드상의 Clusterware stack 상태 확인
| # su – grid $ crsctl check cluster -all ************************************************************** XXXDB01: CRS-4537: Cluster Ready Services is online CRS-4529: Cluster Synchronization Services is online CRS-4533: Event Manager is online ************************************************************** |
- CRS 리소스 상태 확인
| $ crsctl status res -t ——————————————————————- Name Target State Server State details ——————————————————————- Local Resources ——————————————————————- ora.DG_ARCH.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.DG_CRS.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.DG_DATA.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.LISTENER.lsnr ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.asm ONLINE ONLINE XXXDB01 Started,STABLE ONLINE ONLINE XXXDB02 Started,STABLE ora.net1.network ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.ons ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ——————————————————————- Cluster Resources ——————————————————————- ora.LISTENER_SCAN1.lsnr 1 ONLINE ONLINE XXXDB01 STABLE ora.MGMTLSNR 1 ONLINE ONLINE XXXDB01 169.254.110.154 11.0 .0.1,STABLE ora.cvu 1 ONLINE ONLINE XXXDB01 STABLE ora.mgmtdb 1 ONLINE ONLINE XXXDB01 Open,STABLE ora.oc4j 1 ONLINE ONLINE XXXDB01 STABLE ora.scan1.vip 1 ONLINE ONLINE XXXDB01 STABLE ora.XXXDB.db 1 ONLINE ONLINE XXXDB01 Open,STABLE 2 ONLINE ONLINE XXXDB02 Open,STABLE ora.XXXDB01.vip 1 ONLINE ONLINE XXXDB01 STABLE ora.XXXDB02.vip 1 ONLINE ONLINE XXXDB02 STABLE ——————————————————————- |
-
Database 기동과 정지
- DB Instance 기동
- DB Instance 기동
- oracle 계정으로 아래의 명령 중 선택하여 수행하여 DB instance를 기동한다.
| # su – oracle $ srvctl start database -database -d XXXDB — 모든 node의 instance 기동 $ srvctl start instance -d XXXDB -i XXXDB1 — XXXDB1 instance만 기동 |
- 아래의 명령으로 instance 상태를 확인한다.
| $ crsctl stat res -t ——————————————————————- Name Target State Server State details ——————————————————————- Local Resources ——————————————————————- ora.DG_ARCH.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.DG_CRS.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.DG_DATA.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.LISTENER.lsnr ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.asm ONLINE ONLINE XXXDB01 Started,STABLE ONLINE ONLINE XXXDB02 Started,STABLE ora.net1.network ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.ons ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ——————————————————————- Cluster Resources ——————————————————————- ora.LISTENER_SCAN1.lsnr 1 ONLINE ONLINE XXXDB01 STABLE ora.MGMTLSNR 1 ONLINE ONLINE XXXDB01 169.254.110.154 11.0 .0.1,STABLE ora.cvu 1 ONLINE ONLINE XXXDB01 STABLE ora.mgmtdb 1 ONLINE ONLINE XXXDB01 Open,STABLE ora.oc4j 1 ONLINE ONLINE XXXDB01 STABLE ora.scan1.vip 1 ONLINE ONLINE XXXDB01 STABLE ora.XXXDB.db 1 ONLINE ONLINE XXXDB01 Open,STABLE 2 ONLINE ONLINE XXXDB02 Open,STABLE ora.XXXDB01.vip 1 ONLINE ONLINE XXXDB01 STABLE ora.XXXDB02.vip 1 ONLINE ONLINE XXXDB02 STABLE ——————————————————————- |
- DB Instance 정지
- oracle 계정으로 아래의 명령 중 선택하여 수행하여 DB instance를 정지한다.
| # su – oracle $ srvctl stop database -database -d XXXDB — 모든 node의 instance 정지 $ srvctl stop instance -d XXXDB -i XXXDB1 — XXXDB1 instance만 정지 |
- 아래의 명령으로 instance 상태를 확인한다.
| $ crsctl stat res -t ——————————————————————- Name Target State Server State details ——————————————————————- Local Resources ——————————————————————- ora.DG_ARCH.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.DG_CRS.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.DG_DATA.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.LISTENER.lsnr ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.asm ONLINE ONLINE XXXDB01 Started,STABLE ONLINE ONLINE XXXDB02 Started,STABLE ora.net1.network ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.ons ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ——————————————————————- Cluster Resources ——————————————————————- ora.LISTENER_SCAN1.lsnr 1 ONLINE ONLINE XXXDB01 STABLE ora.MGMTLSNR 1 ONLINE ONLINE XXXDB01 169.254.110.154 11.0 .0.1,STABLE ora.cvu 1 ONLINE ONLINE XXXDB01 STABLE ora.mgmtdb 1 ONLINE ONLINE XXXDB01 Open,STABLE ora.oc4j 1 ONLINE ONLINE XXXDB01 STABLE ora.scan1.vip 1 ONLINE ONLINE XXXDB01 STABLE ora.XXXDB.db 1 OFFLINE OFFLINE XXXDB01 Instance Shutdown,ST ABLE 2 ONLINE ONLINE XXXDB02 Open,STABLE ora.XXXDB01.vip 1 ONLINE ONLINE XXXDB01 STABLE ora.XXXDB02.vip 1 ONLINE ONLINE XXXDB02 STABLE ——————————————————————- |
-
Listener 기동과 정지
- Listener 기동
- Listener 기동
- grid 계정으로 아래의 명령을 수행하여 Listener를 기동한다.
| # su – grid $ srvctl start listener -n XXXDB01 — XXXDB01 node의 listener 기동 |
- 아래의 명령으로 listener 상태를 확인한다.
| $ crsctl stat res -t ——————————————————————- Name Target State Server State details ——————————————————————- Local Resources ——————————————————————- ora.DG_ARCH.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.DG_CRS.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.DG_DATA.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.LISTENER.lsnr ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.asm ONLINE ONLINE XXXDB01 Started,STABLE ONLINE ONLINE XXXDB02 Started,STABLE ora.net1.network ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.ons ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ——————————————————————- Cluster Resources ——————————————————————- ora.LISTENER_SCAN1.lsnr 1 ONLINE ONLINE XXXDB01 STABLE ora.MGMTLSNR 1 ONLINE ONLINE XXXDB01 169.254.110.154 11.0 .0.1,STABLE ora.cvu 1 ONLINE ONLINE XXXDB01 STABLE ora.mgmtdb 1 ONLINE ONLINE XXXDB01 Open,STABLE ora.oc4j 1 ONLINE ONLINE XXXDB01 STABLE ora.scan1.vip 1 ONLINE ONLINE XXXDB01 STABLE ora.XXXDB.db 1 ONLINE ONLINE XXXDB01 Open,STABLE 2 ONLINE ONLINE XXXDB02 Open,STABLE ora.XXXDB01.vip 1 ONLINE ONLINE XXXDB01 STABLE ora.XXXDB02.vip 1 ONLINE ONLINE XXXDB02 STABLE ——————————————————————- |
- Listener 정지
- grid 계정으로 아래의 명령을 수행하여 Listener를 정지한다.
| # su – grid $ srvctl stop listener -n XXXDB01 — XXXDB01 node의 listener 정지 |
- 아래의 명령으로 listener 상태를 확인한다.
| $ crsctl stat res -t ——————————————————————- Name Target State Server State details ——————————————————————- Local Resources ——————————————————————- ora.DG_ARCH.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.DG_CRS.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.DG_DATA.dg ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.LISTENER.lsnr OFFLINE OFFLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.asm ONLINE ONLINE XXXDB01 Started,STABLE ONLINE ONLINE XXXDB02 Started,STABLE ora.net1.network ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ora.ons ONLINE ONLINE XXXDB01 STABLE ONLINE ONLINE XXXDB02 STABLE ——————————————————————- Cluster Resources ——————————————————————- ora.LISTENER_SCAN1.lsnr 1 ONLINE ONLINE XXXDB01 STABLE ora.MGMTLSNR 1 ONLINE ONLINE XXXDB01 169.254.110.154 11.0 .0.1,STABLE ora.cvu 1 ONLINE ONLINE XXXDB01 STABLE ora.mgmtdb 1 ONLINE ONLINE XXXDB01 Open,STABLE ora.oc4j 1 ONLINE ONLINE XXXDB01 STABLE ora.scan1.vip 1 ONLINE ONLINE XXXDB01 STABLE ora.XXXDB.db 1 ONLINE ONLINE XXXDB01 Open,STABLE 2 ONLINE ONLINE XXXDB02 Open,STABLE ora.XXXDB01.vip 1 ONLINE ONLINE XXXDB01 STABLE ora.XXXDB02.vip 1 ONLINE ONLINE XXXDB02 STABLE ——————————————————————- |
-
Database 사용자 관리
- User의 생성
- User의 생성
- Password와 Default Tablespace 및 Temporary Tablespace를 지정하여 User 생성
| $ sqlplus “/as sysdba” SQL> create user test_user identified by test_user default tablespace test_data temporary tablespace test_tmp; |
- 새로운 User 권한 부여
- 관리자가 User를 생성하면 해당 User에게 각각 필요한 권한을 부여할 수 있다.
- 다음 명령어를 통하여 User로 접속 가능하도록 할 수 있는 권한과 Object를 생성할 수 있는 권한을 부여한다.
| $ sqlplus “/as sysdba” SQL> grant resource, connect to test_user; |
- User 패스워드 변경
- 다음 명령어를 통하여 password를 test로 변경할 수 있다.
| $ sqlplus “/as sysdba” SQL> alter user test_user identified by test |
- User 삭제
- 다음 명령어를 통하여 User를 삭제할 수 있다.
| $ sqlplus “/as sysdba” SQL> drop user test_user cascade; |
※ 참고 : cascade option을 이용할 경우 test_user 계정의 스키마는 물론 종속적인 foreign key 까지도 drop 시킨다. 그러므로 이용 시 주의해야 한다.
-
Database tablespace 관리
- Tablespace 종류
- Tablespace 종류
- System tablespace
Oracle의 Dictionary 가 저장되는 영역으로 재생성은 불가능 하다. Database 당 하나의 System Tablespace가 존재한다. - Undo tablespace
Undo Segment 가 저장되는 공간으로 RAC 의 경우 Instance 각각 독립적인 Undo Tablespace를 가진다. 읽기의 일관성 유지해 줍니다. - Temp tablespace
임시 영역으로 SGA에서 수행할 수 없는 Sort등의 작업 시 사용된다. - Data tablespace
Table 이 저장되는 영역으로 Table 생성시 사용자 임의로 지정한다.
- Tablespace 추가 및 삭제
| 구분 | 파일 구분 | SQL 수행 |
| 파일 추가 | Datafile | alter tablespace test_data add datafile ‘+DG_DATA’ size 30000M; |
| TEMP File | alter tablespace test_tmp add tempfile ‘+DG_DATA’ size 30000M; | |
| 신규 생성 | Data TBS | create tablespace test_data datafile ‘+DG_DATA’ size 30000M; |
| TEMP TBS | create temporary tablespace test_tmp tempfile ‘+DG_DATA’ size 30000M; | |
| UNDO TBS | create undo tablespace UNDOTBS1 datafile ‘DG_DATA’ size 30000M; | |
| 삭제 | drop tablespace test_data including contents and datafiles; |
-
Tablespace 관리
- 테이블스페이스 사용률 조회
- 테이블스페이스 사용률 조회
| select * from ( select df.tablespace_name tablespace_name, round(df.total_bytes/1024/1024,2) total_MB, round((df.total_bytes-fs.free_bytes)/1024/1024,2) used_MB, round(((df.total_bytes-fs.free_bytes)/df.total_bytes)*100,2) used_pct, round(fs.free_bytes/1024/1024,2) free_MB from (select tablespace_name, sum(bytes) total_bytes from dba_data_files group by tablespace_name) df, (select tablespace_name,sum(bytes) free_bytes,max(bytes) max_free from dba_free_space group by tablespace_name) fs where df.tablespace_name = fs.tablespace_name(+) union all select c.tablespace_name, round(sum(b.bytes)/1024/1024,2) total_MB, round(sum(a.bytes_used)/1024/1024,2) used_MB, round((sum(a.bytes_used)/sum(b.bytes))*100,2) used_pct, round((sum(b.bytes)-sum(a.bytes_used))/1024/1024,2) free_mb from (select bytes_used, file_id from v$temp_extent_pool) a, (select bytes, file#, name from v$tempfile) b, (select file_name, file_id, tablespace_name from dba_temp_files) c where a.file_id=b.file# and b.file#=c.file_id group by c.tablespace_name ) order by 4 desc; TABLESPACE_NAME TOTAL_MB USED_MB USED_PCT FREE_MB —————————— ———- ———- ———- ———- SYSTEM 1024 617.38 60.29 406.63 SYSAUX 1024 451.88 44.13 572.13 UNDOTBS1 1024 180.56 17.63 843.44 UNDOTBS2 1024 136 13.28 888 USERS 500 1.38 .28 498.63 TEMP 1024 0 0 1024 |
- ASM diskgroup 사용률 조회
- 다음 명령어를 통하여 User를 삭제할 수 있다.
| SELECT name, free_mb, total_mb, round(free_mb/total_mb*100,2) as percentage FROM v$asm_diskgroup; NAME FREE_MB Total Size (MB) PERCENTAGE —————————— ———- ————— ———- DG_CRS 576 10240 5.63 DG_DATA 718312 1013756 70.86 DG_ARCH 506621 511996 99.0 |
-
Automatic Storage Management (ASM)
-
ASM 구조
- ASM 개요
ASM은 특정 데이터에 대한 복사본을 자기 자신의 디스크에 유지할 수 있기 때문에 Software 미러링 효과를 볼 수 있다. 이처럼 ASM은 데이터에 대한 안정성, 그리고 성능을 어떻게 유지할 것인가에 대해 상당히 유연하게 달리 지정할 수 있다.
ASM을 단순히 기존 파일시스템, RAW Device와 같은 파일 저장소로 간과하면 큰 오산이다. ASM은 여타 디스크 Solution 없이 Striping / Mirroring 효과를 볼 수 있을 뿐만 아니라, 자동적으로 데이터 구성을 재 분배할 수 있는 기능을 제공해 줌으로써, 더 이상 I/O tuning을 할 필요로 없게 만들고 있다. 또한, 자체가 Cluster 파일시스템 이기 때문에 하나 이상의 노드에 있는 다른 데이터베이스에 대해서도 통합 관리가 가능한 것이다. DBA들은 더 이상 스토리지 관리를 위해 엄청난 시간을 투자할 필요가 없게 되었다. - ASM 개요
- ASM은 기존 데이터베이스 구성과 독립적으로 관리될 수 있다. 즉, 기존 데이터베이스가 데이터 저장소로 파일시스템을 사용하고 있어도, 아니면 RAW Device를 사용하고 있어도 이와는 별도로 새로운 데이터파일을 ASM에 저장/관리할 수 있는 것이다. 기존 데이터 파일들은 ASM 관리 영역으로 이관될 수도 있다.
- ASM이 관리하는 모든 디스크에 대해 load balancing 작업을 자동적으로 처리해 줌으로써, 특정 디스크에 load가 집중되는 hot spot 현상을 최소화 할 수 있으며, 이로 인해 성능을 극대화 할 수 있다. 또한, 데이터가 디스크에 균등한 크기로 저장/관리되어 fragmentation 현상이 발생하지 않는다. 그리고, ASM이 관리하는 영역에서 새로운 디스크가 추가되거나 삭제될 때마다, 기존 데이터들에 대해 재구성 작업이 자동적으로 일어난다.
-
- ASM의 기본 개념
- Oracle 10g부터 지원되는 Volume Manager와 File system의 통합체
- Oracle 데이터베이스 파일을 위해 특별히 구현된 Storage 관리 시스템
- Disk간 Balance가 유지될 수 있도록 분산 저장, Mirroring을 지원
-
Oracle은 Volume Manager, File System, Raw Device 등의 방법 대신 ASM의 사용을 권장하고 있음 (11g부터는 Raw Device는 공식적으로 지원되지 않음)

- ASM 주요 기능 및 특징
| 구분 | 내용 |
| 관리 복잡성 제거 |
|
| 스토리지 제품 구입비용 절약 |
|
| 성능/확장/안전성 증대 |
|
| RAC (Real Application Cluster) 지원 |
|
- ASM 및 타사 File System 대응 File Type 비교
| 구분 | Local File System | Cluster File System | ASM | NAS/NFS | Raw/Block Device |
| Oracle Software | YES | YES | NO | YES | NO |
| Application Related Files | YES | YES | NO | YES | NO |
| Clusterware Configuration | NO | YES | YES | YES | YES |
| Principal Database Files | YES | YES | YES | YES | YES |
| Database Archived log | YES | YES | YES | YES | NO |
| Database External Files | YES | YES | NO | YES | NO |
| RMAN Backup Files | YES | YES | YES | YES | NO |
-
ASM Instance의 개념RAC 클러스터에서 ASM을 사용하려면 각각의 노드에서 ASM 인스턴스가 실행되고 있어야 한다 ASM 인스턴스는 ASM 디스크그룹의 메타데이터 관리 및 데이터베이스 인스턴스를 지원한다. 다른 데이터베이스 인스턴스가 ASM 스토리지에 있는 파일에 접근하기 전에 ASM 인스턴스가 구동되어 있어야 한다 ASM 인스턴스가 종료되면 모든 클라이언트 데이터베이스 인스턴스도 종료된다. 또한, ASM 인스턴스는 디스크 추가, 제거, 리밸런싱 작업을 처리한다.
- ASM Instance의 특징
- ASM Instance의 특징
| 구분 | 내용 |
| 구조 |
|
| 관리정보 |
|
| 장애/복구 |
|
- ASM Instance
- DB instance와 같은 구조로 생성 (smaller SGA, BG processes)
- Cluster 환경에서 Node 당 하나의 ASM INSTANCE 를 가진다.
- ASM 파일(Diskgroup)을 DB 에서 share할 수 있도록 마운트 및 연결
- Init+ASM.ora 파일에서 파라미터 변경가능(asm설치시 orapwd및 spfile생성)
- Disk Group 에 대한 Meta data를 관리한다.
- ASM Metadata 는 디스크 그룹 관리를 위한 정보를 담고 있고, 생성된 디스크 그룹 내에 저장.
- ASM Instance Processes
| Process | 내용 |
| ARBn | ASM Rebalance를 수행하는 프로세스. 평상시엔 떠 있지 않다가 실제로 Rebalance를 수행하게 되면 나타남. |
| RBAL | ASM Rebalance를 담당하는 프로세스. Rebalance작업을 관리하며, 각 그룹에 할당된 모든 디스크에 대하여 데이터 재분배를 수행하게 됨. 이 프로세스는 항상 떠있으며, 사용자의 명령을 위해 대기 함. |
| GMON | ASM 디스크 그룹 내 디스크 멤버십을 관리 |
| ASMB | 데이터베이스 인스턴스 상에서 동작하며, ASM 인스턴스의 Foreground process와 통신 함. 주기적인 message 교환을 통해 통계정보를 공유하고, ASM과 데이터베이스 인스턴스 heartbeat 를 통한 health check을 수행. |
| MARK | Offline 디스크에 대한 재 동기화를 위해 ASM 할당 단위를 표시 하기 위한 프로세스. |
| Onnn | 메시지를 교환하는 ASM 인스턴스에 대한 연결 풀을 형성하는 하나이상의 ASM 슬레이브 프로세스 |
| PZ9n | 하나이상의 병렬 슬레이브 프로세스. |
| ORBn | Rebalance시 ASM data extent의 이동을 담당하는 프로세스, ASM data extent의 이동이 발생하면 순간적으로 프로세스 개수가 여러 개 생길 수 있음. |
-
ASM 디스크
- ASM DiskGroup
- ASM DiskGroup
- ASM 에 의해 관리되는 최상위 객체.
- 논리적 단위로써 관리되는 ASM Disks의 집합체
- 각각의 디스크 그룹 내에 디스크 그룹의 메타데이터 정보를 저장.
- 하나의 디스크 그룹이 여러 개의 database에 의해 공유될 수 있고, 하나의 database가 여러 개의 디스크 그룹을 사용할 수도 있다.
- ASM mirroring Option
- ASM은 ASM 디스크그룹에 대해 다음 세 가지 중복 구성 유형을 제공한다.
| Disk Group Type | Supported Mirroring Levels | Default Mirroring Level |
| External redundancy | Unprotected (none) | Unprotected |
| Normal redundancy | Two-way Three-way Unprotected (None) |
Two-way |
| High redundancy | Three-way | Three-way |
- 외부 중복 구성(External redundancy)은 어떠한 미러링도 하지 않는다. 이것은 RAID나 LVM 같은 기존 운영체제나 스토리지 어레이의 보호 기능을 사용한다. 하지만 외부 중복 구성을 선택했을 경우 하부 스토리지가 올바르게 구성되었는지 확인하는 것은 사용자의 책임이다. ASM은 장애 발생 시 복구를 보장하지 않는다. 또한, 외부 중복 구성을 사용할 경우 어떠한 failure group도 정의할 필요가 없다.
- 일반 중복 구성(Normal redundancy)은 기본 설정이며 한 개의 주 extent와 한 개의 미러 extent를 사용하여 각 파일 extent를 두 개의 디스크그룹에 기록하는 이중 미러링을 구현한다. 일반 중복 구성을 보장하려면 최소 두 개의 failure group을 정의해야 한다.
- 높은 중복 구성(High redundancy)은 각각의 파일 extent가 한 개의 주 extent와 두 개의 미러 extent를 사용하여 세 개의 디스크그룹에 기록하는 삼중 미러링으로 구현되어 있다. 높은 중복 구성을 보장하려면 최소 세 개의 failure group을 정의해야 한다.
- Failure Group
디스크 컨트롤러에 장애가 발생하면 연결된 모든 디스크에는 접근할 수 없다 ASM은 컨트롤러 같은 단일 장애 지점 에 영향을 받는 디스크를 그룹화하여 failure group으로 정의한다. 중복 구성을 보장하기 위해 각각의 미러는 서로 다른 failure group에 위치해야 한다. 따라서 컨트롤러 장애 같은 상황이 발생했을 때. ASM은 다른 디스크그룹에 미러링 된 extent의 사본을 사용하여 장애가 발생한 디스크그룹을 재구성할 수 있다.
- 장애 발생시 동일하게 영향을 받게 되는, 공통의 리소스를 공유하는 디스크의 집합체
- Failure Group은 Data의 Copy 본을 저장하는 목적으로 사용됨
- Normal Redundancy를 사용하는 File의 경우 Oracle ASM은 서로 다른 Failure Group에 속하는 Primary Copy와 Secondary Copy를 할당함
- Failure Group 할당 시 동일 H/W 구성요소를 사용하지 않거나 해당 H/W 구성 요소가 이중화된 Diskgroup으로 설정해야 함
- Extent의 중복된 복사본은 분리된 Failure Group 에 저장
- Default는 디스크 이름과 Failure group의 디스크로 구성
- Disk controller 별로 failure Group 의 디스크로 구성
- DBA나 ASM에 의해 자동으로 지정됨
- Striping
ASM은 I/0 성능을 최적화하기 위해 디스크그룹의 디스크에 파일을 분산하여 스트라이핑 한다. 따라서 디스크그룹 내의 모든 디스크는 동일한 유형과 성능 특성을 가져야 한다. 스트라이핑의 두 가지 유형은 coarse와 fine이며, 데이터베이스 파일 유형에 따라 어느 방식을 사용할지 결정된다
Coarse 스트라이핑은 데이터베이스 파일, 트랜스포터블 테이블스페이스(transportable tablespaces), 백업세트, 덤프세트, 컨트롤 파일 자동 백업, 블록 변경 추적 파일(block change tracking file), 데이터 가드 구성 파일 등 대부분의 파일 유형에 사용된다.
또한 fine 스트라이핑은 컨트롤 파일, 온라인 리두 로그, 플래시백 로그에만 사용된다.
- Rebalancing
- File이 Disk Group내에서 보다 균등하게 분포하도록 조정하는 작업
- Data가 Disk에 균등히 분포할 경우 Load Balancing은 자동으로 이루어짐
- Rebalancing은 자동/수동으로 이루어질 수 있으며 자동으로 이루어지는 경우는 Storage Configuration이 변경되는 경우에 발생.
- Rebalancing 수행 중에도 Database는 정상적으로 운영될 수 있음
- 다만 Rebalancing 작업이 Disk I/O 자원을 많이 사용할 수 있으며 이에 따른 Online 성능 저하 현상을 최소화 하기 위해 Power Setting Parameter (ASM_POWER_LIMIT)를 통해 Rebalancing에 의한 I/O 사용량을 제한할 수 있음
- Mirroring
ASM은 데이터를 중복 구성하기 위해 미러링을 사용하며 파일 레벨에서 extent를 미러링 한다. 이것은 디스크 레벨에서 미러링을 수행하는 대부분의 운영체제 미러링과 다르다. ASM 디스크가 손실된 경우, 다른 ASM 디스크에 미러링 된 extent를 사용하여 데이터 손실이나 서비스 중단 없이 작업을 계속할 수 있다. 디스크 장애가 발생한 경우, ASM은 통일 그룹의 다른 디스크에 미러링 된 extent를 사용하여 망가진 extent를 재구성할 수 있다.
미러링은 Diskgroup 생성 (또는 변경) 시 Failure Group을 정의할 수 있으며 Failure Group은 Disk Group Type을 Normal Redundancy / High Redundancy 로 설정할 경우만 유효하다.
-
ASM 모니터링 및 관리하기
- ASM Instance 접속
- ASM Instance 접속
| [grid@rac12c01 ~]$ sqlplus / as sysasm SQL*Plus: Release 12.1.0.2.0 Production on Wed Jun 3 09:14:34 2015 Copyright (c) 1982, 2014, Oracle. All rights reserved. Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 – 64bit Production With the Real Application Clusters and Automatic Storage Management options SQL> select instance_name, status from v$instance; INSTANCE_NAME STATUS —————- ———— +ASM1 STARTED |
오라클은 각 노드에 하나의 ASM 인스턴스만 존재할 수 있으며, 인스턴스 이름은 수정할 필요가 없다. 인스턴스 이름은 ASM 리소스의 리소스 프로파일 내부에 정의되며, crsctl status resource ora.asm -p 명령어를 사용하여 이를 조회할 수 있다. 다음 예제처럼 생성된 인스턴스 이름을 확인할 수 있다. 일반적으로 1번 노드 ASM Instance 이름은 +ASM1, 2번 노드 ASM Instance 이름은 +ASM2가 된다.
| [root@rac12c01 ~]# crsctl status resource ora.asm -p NAME=ora.asm TYPE=ora.asm.type […] GEN_USR_ORA_INST_NAME@SERVERNAME(XXXDB01)=+ASM1 GEN_USR_ORA_INST_NAME@SERVERNAME(XXXDB02)=+ASM2 |
- ASM Diskgroup Creation
디스크그룹은 asmca, asmcmd, EM(엔터프라이즈 관리자)을 사용하여 생성할 수 있다 또한, 다음 ASM 인스턴스의 SQL Plus로 접속하여 CREATE DISKGROUP 명령어를 사용해 수동으로 생성할 수도 있다.
- 디스크 그룹 확인
| SQL> select group_number, name, state from v$asm_diskgroup; GROUP_NUMBER NAME STATE ———— —————————— ———– 1 DG_CRS MOUNTED 2 DG_DATA MOUNTED 3 DG_ARCH MOUNTED |
- 추가 할 디스크 확인
| SQL> select group_number,mount_status,path,total_mb from v$asm_disk where mount_status=’CLOSED’; GROUP_NUMBER MOUNT_S PATH TOTAL_MB ———— ——- ———————————– ———- 0 CLOSED /dev/sdb3 0 |
-
Disk Group 생성일단 CREATE DISKGROUP 명령어가 시작되면 ASM은 새로 생성된 디스크그룹을 자동으로 마운트한다. 동적 성능 뷰 GV$ASM_DISKGROUP을 조회하여 전체 클러스터 노드의 신규 ASM 디스크그룹 상태를 점검할 수 있다.
| SQL> create diskgroup ORATEST external redundancy disk ‘/dev/sdb3’; Diskgroup created. SQL> select group_number,mount_status,path,total_mb 2 from v$asm_disk 3 where mount_status=’CLOSED’; no rows selected SQL> select group_number,name,state from v$asm_diskgroup; GROUP_NUMBER NAME STATE ———— —————————— ———– 1 DG_CRS MOUNTED 2 DG_DATA MOUNTED 3 DG_ARCH MOUNTED 4 ORATEST MOUNTED |
- ASM Disk group Drop
커맨드를 통해서 diskgroup을 drop 할 수 있다. 이를 위해 sysasm으로 접속하여 drop diskgroup diskgroupName 명령어를 실행한다. 이 명령어는 diskgroup이 비어있지 않으면 오류를 발생한다. 파일을 수동으로 삭제하거나 including contents 절을 지정하여 삭제한다.
| SQL> select group_number,name,state from v$asm_diskgroup; GROUP_NUMBER NAME STATE ———— —————————— ———– 1 DG_CRS MOUNTED 2 DG_DATA MOUNTED 3 DG_ARCH MOUNTED 4 ORATEST MOUNTED SQL> drop diskgroup oratest; Diskgroup dropped. SQL> select group_number,name,state from v$asm_diskgroup; GROUP_NUMBER NAME STATE ———— —————————— ———– 1 DG_CRS MOUNTED 2 DG_DATA MOUNTED 3 DG_ARCH MOUNTED |
- ASM Disk group Mount/Umount
Init+ASM.ora 파일에 asm_diskgroups 항목에 지정된 diskgroup는 자동으로 asm instance 시작 시에 mount된다. ASM 디스크그룹을 수동으로 마운트하려면, alter diskgroup diskgroupName mount 명령어를 사용한다.
| SQL> select group_number,name,state from v$asm_diskgroup; GROUP_NUMBER NAME STATE ———— —————————— ———– 1 DG_CRS MOUNTED 2 DG_DATA MOUNTED 3 DG_ARCH MOUNTED 4 ORATEST MOUNTED SQL> alter diskgroup ORATEST dismount; Diskgroup altered. SQL> select group_number,name,state from v$asm_diskgroup; GROUP_NUMBER NAME STATE ———— —————————— ———– 1 DG_CRS MOUNTED 2 DG_DATA MOUNTED 3 DG_ARCH MOUNTED 4 ORATEST DISMOUNTED SQL> alter diskgroup ORATEST mount; Diskgroup altered. SQL> select group_number,name,state from v$asm_diskgroup; GROUP_NUMBER NAME STATE ———— —————————— ———– 1 DG_CRS MOUNTED 2 DG_DATA MOUNTED 3 DG_ARCH MOUNTED 4 ORATEST MOUNTED |
- ASM Disk group disk add
아무리 신중하게 계획했더라도 ASM 디스크그룹의 증설이 필요할 수 있다. ASM 디스크그룹 증설은 일단 전체 클러스터 노드에 블록 디바이스를 제공하고 나면 비교적 간단한 작업이다. ASM에 새 LUN을 추가할 때, 기존 ASM 디스크와 성능과 크기가 통일하거나 가급적 비슷한 디스크를 사용하는 것이 좋다.
Rebalance power 옵션은 asm_power_limit parameter (default 1)의 수치를 해당 operation에 한해 일시적으로 조정하는 옵션이다. 이 수치가 높을수록 disk 추가, 삭제 시에 발생하는 rebalancing 작업이 빠르게 진행된다. (수치가 높을 수록 disk i/o 점유율이 높음)
| SQL> select group_number,mount_status,path,total_mb 2 from v$asm_disk where mount_status=’CLOSED’; GROUP_NUMBER MOUNT_S PATH TOTAL_MB ———— ——- —————————— ——— 0 CLOSED /dev/sdb3 0 SQL> select b.name as group_name, 2 a.name as disk_name, 3 a.header_status, 4 a.state, 5 a.free_mb 6 from v$asm_disk a, 7 v$asm_diskgroup b 8 where a.group_number=b.group_number; GROUP_NAME DISK_NAME HEADER_STATU STATE FREE_MB ————- ————— ———— ——– ——— ORATEST ORATEST_0000 MEMBER NORMAL 5064 DG_DATA DG_DATA_0000 MEMBER NORMAL 2904 DG_CRS DG_CRS_0000 MEMBER NORMAL 2891 DG_ARCH DG_ARCH_0000 MEMBER NORMAL 2857 SQL> alter diskgroup ORADATA add disk ‘/dev/sdb3’ rebalance power 10; Diskgroup altered. |
위 명령어 프롬프트는 거의 즉시 반환되지만 백그라운드에서 리밸런싱 작업이 일어난다. V$ASM_OPERATION 뷰를 조회하여 리밸런싱 작업에 걸리는 시간을 추정할 수 있다.
| SQL> select d.name, o.operation, o.state, o.power, o.est_minutes 2 from v$asm_disk d, v$asm_operation o 3 where d.group_number=o.group_number 4 order by 1; NAME OPERA STAT POWER EST_MINUTES ——————– —– —- ———- ———– DG_DATA_0000 REBAL RUN 10 0 DG_DATA_0000 REBAL WAIT 10 0 DG_DATA_0001 REBAL WAIT 10 0 DG_DATA_0001 REBAL RUN 10 0 |
- ASM Disk group disk drop
디스크를 drop하면 rebalancing 작업이 일어난다. V$ASM_DISK 뷰에서 제거 대상 디스크의HEADER STATUS가 FORMER인 경우에만 클러스터에서 ASM 디스크를 물리적으로 안전하게 제거할 수 있다. 디스크그룹에서 디스크를 drop 하려면 ALTER DISKGROUP 명령어를 사용한다.
| SQL> select b.name as group_name, 2 a.name as disk_name, 3 a.header_status, 4 a.state, 5 a.free_mb 6 from v$asm_disk a, 7 v$asm_diskgroup b 8 where a.group_number=b.group_number; GROUP_NAME DISK_NAME HEADER_STATU STATE FREE_MB ————- ————— ———— ——– ——— ORATEST ORATEST_0000 MEMBER NORMAL 5064 DG_DATA DG_DATA_0000 MEMBER NORMAL 2904 DG_DATA DG_DATA_0001 MEMBER NORMAL 2904 DG_CRS DG_CRS_0000 MEMBER NORMAL 2891 DG_ARCH DG_ARCH_0000 MEMBER NORMAL 2857 SQL> alter diskgroup ORADATA drop disk DG_DATA_0001 rebalance power 3; Diskgroup altered. |
disk drop 명령실행 후 add와 마찬가지로 내부적으로 리밸런싱 작업이 진행된다.
| SQL> select d.name, o.operation, o.state, o.power, o.est_minutes 2 from v$asm_disk d, v$asm_operation o 3 where d.group_number=o.group_number 4 order by 1; NAME OPERA STAT POWER EST_MINUTES —————————— —– —- ———- ———– DG_DATA_0000 REBAL RUN 3 0 DG_DATA_0000 REBAL WAIT 3 0 DG_DATA_0001 REBAL WAIT 3 0 DG_DATA_0001 REBAL RUN 3 0 SQL> select d.name, o.operation, o.state, o.power, o.est_minutes 2 from v$asm_disk d, v$asm_operation o 3 where d.group_number=o.group_number 4 order by 1; NAME OPERA STAT POWER EST_MINUTES —————————— —– —- ———- ———– DG_DATA_0000 REBAL WAIT 3 DG_DATA_0000 REBAL DONE 3 |
- ASM Disk size 변경
ASM DISK의 size를 변경 할 수 있는 방법이 있다. 디스크를 size 없이 추가 했을 때, 해당 디스크는 할당 할 수 있는 영역까지 디스크 용량을 잡는다. 만약 디스크를 추가 할 때 사이즈를 줬다면 추가적으로 사이즈를 더 줄 수 있다.
| SQL> select b.name as group_name , 2 a.name as disk_name, 3 a.header_status, 4 a.state, 5 a.total_mb 6 from v$asm_disk a, 7 v$asm_diskgroup b 8 where a.group_number=b.group_number; GROUP_NAME DISK_NAME HEADER_STATU STATE FREE_MB ————- ————— ———— ——– ——— ORATEST ORATEST_0000 MEMBER NORMAL 8064 DG_DATA DG_DATA_0000 MEMBER NORMAL 2904 DG_CRS DG_CRS_0000 MEMBER NORMAL 2891 DG_ARCH DG_ARCH_0000 MEMBER NORMAL 2857 SQL> alter diskgroup ORATEST resize disk ORATEST_0000 size 5000m; Diskgroup altered. SQL> select b.name as group_name , 2 a.name as disk_name, 3 a.header_status, 4 a.state, 5 a.total_mb 6 from v$asm_disk a, 7 v$asm_diskgroup b 8 where a.group_number=b.group_number; GROUP_NAME DISK_NAME HEADER_STATU STATE FREE_MB ————- ————— ———— ——– ——— ORATEST ORATEST_0000 MEMBER NORMAL 5000 DG_DATA DG_DATA_0000 MEMBER NORMAL 2904 DG_CRS DG_CRS_0000 MEMBER NORMAL 2891 DG_ARCH DG_ARCH_0000 MEMBER NORMAL 2857 |
- ASM check Disk
디스크 그룹의 정합성을 체크할 수 있으며, 수행 결과는 ASM Instance의 Alert.log에 기록된다. 단 Diskgroup 이 mount 상태 일 때 만 check 가 가능하다.
| SQL> conn / as sysasm Connected. SQL> alter diskgroup ORATEST check all -> alert log 확인 Sun Jun 07 07:35:07 2015 NOTE: starting check of diskgroup ORATEST Sun Jun 07 07:35:07 2015 GMON querying group 3 at 25 for pid 36, osid 36035 GMON checking disk 0 for group 3 at 26 for pid 36, osid 36035 Sun Jun 07 07:35:07 2015 SUCCESS: check of diskgroup ORATEST found no errors Sun Jun 07 07:35:07 2015 SUCCESS: alter diskgroup ORATEST check all |
-
Oracle Software 변경 관리
- Patch 적용 Process
- Patch 적용 Process
- 평상시 : 운영장비로의 Patch 적용은 사전에 테스트 장비를 이용하여 적용한 후 일정 시간 모니터링 후 적용한다.
- 긴급 상황 시 : 긴급하게 조치해야 할 장애를 위한 패치는 경우에 따라 테스트 장비에서의 점검 프로세스를 생략할 수도 있다.
- 적용된 패치 확인
- 다음 명령어를 통하여 적용된 패치를 확인할 수 있다.
| $ opatch lsinventory Oracle Interim Patch Installer version 12.1.0.1.7 Copyright (c) 2015, Oracle Corporation. All rights reserved. Oracle Home : /oracle/12.1.0.2 Central Inventory : /grid/oraInventory from : /oracle/12.1.0.2/oraInst.loc OPatch version : 12.1.0.1.7 OUI version : 12.1.0.2.0 Log file location : /oracle/12.1.0.2/cfgtoollogs/opatch/opatch2015-06-18_00-20-31AM_1.log Lsinventory Output file location : /oracle/12.1.0.2/cfgtoollogs/opatch/lsinv/lsinventory2015-06-18_00-20-31AM.txt ——————————————————————————– Local Machine Information:: Hostname: ktms1 ARU platform id: 267 ARU platform description:: Solaris Operating System (x86-64) Installed Top-level Products (1): Oracle Database 12c 12.1.0.2.0 There are 1 products installed in this Oracle Home. Interim patches (2) : Patch 20299023 : applied on Thu Jun 18 00:06:44 KST 2015 Unique Patch ID: 18672617 Patch description: “Database Patch Set Update : 12.1.0.2.3 (20299023)” Created on 18 Mar 2015, 00:15:50 hrs PST8PDT Sub-patch 19769480; “Database Patch Set Update : 12.1.0.2.2 (19769480)” Bugs fixed: 19189525, 19065556, 19075256, 19723336, 19077215, 19865345, 18845653 19280225, 19524384, 19248799, 18988834, 19048007, 18288842, 19238590 18921743, 18952989, 16870214, 19928926, 19134173, 19180770, 19018206 19197175, 19149990, 18849537, 19730508, 19183343, 19012119, 19001390 18202441, 19067244, 19189317, 19644859, 19358317, 19390567, 20074391 19279273, 19706965, 19068970, 19841800, 19512341, 14643995, 19619732 20348653, 18607546, 18940497, 19670108, 19649152, 19065677, 19547370 18948177, 19315691, 19637186, 19676905, 18964978, 19035573, 19176326 18967382, 19174430, 19176223, 19532017, 18674047, 19074147, 19054077 19536415, 19708632, 19289642, 20425790, 19335438, 18856999, 19371175 19468347, 19195895, 19154375, 16359751, 18990693, 19439759, 19769480 19272708, 19978542, 19329654, 19873610, 19174521, 19520602, 19382851 19658708, 19304354, 19052488, 19291380, 18681056, 19896336, 17835294 19076343, 19791377, 19068610, 19561643, 18618122, 20440930, 18456643 18909599, 19487147, 19143550, 19185876, 19016730, 18250893, 20347562 19627012, 16619249, 18354830, 19577410, 19687159, 19001359, 19174942 19518079, 18610915, 18674024, 18306996, 19309466, 19081128, 19915271 19157754, 19058490, 20284155, 18791688, 18885870, 19303936, 19434529 19018447, 18417036, 19597439, 20235511, 19022470, 18964939, 19430401 19044962, 19385656, 19501299, 17274537, 19409212, 19440586, 19606174 18436647, 19023822, 19684504, 19178851, 19124589, 19805359, 19024808 19597583, 19155797, 19393542, 19050649, 19028800 Patch 20299022 : applied on Wed Jun 17 23:59:08 KST 2015 Unique Patch ID: 18594999 Patch description: “OCW Patch Set Update : 12.1.0.2.3 (20299022)” Created on 7 Apr 2015, 11:40:43 hrs UTC Bugs fixed: 18589889, 19139608, 19280860, 19061429, 19133945, 19341538, 18946768 19135521, 19361757, 19187207, 19302350, 19130141, 19530755, 19699720 19168690, 19266658, 18899171, 19244316, 19653795, 18330979, 19471722 18634372, 19027351, 18707416, 19184188, 19131709, 20235486, 19925992 20006646, 18991776, 18439295, 19380733, 18943696, 19550195, 18135723 19163425, 20014326, 19524857, 18849021, 18890943, 18861196, 19154753 17940721, 19522313, 18748932, 18835283, 19184765, 19499021, 19046190 19051385, 19682695, 19050688, 19831611, 19226141, 19053891, 18871287 18998228, 18922918, 18980002, 19683886, 18956780, 18777835, 19026993 17338864, 18261648, 19513650, 19702758, 18952577, 17447588, 19414274 20752167, 19262534, 19147513, 19473088, 19178517, 19529729, 19455563 19319904, 18703978, 20340620, 18536826, 19703246, 19292605, 19192901 20660273, 20011635, 19479503, 19029647, 19179158, 18901356, 19140712 18964974, 18835366, 19184276, 19013789, 19207286, 20510208, 20001507 18950232, 20079414, 19680763, 19259765, 19148791, 19556820, 19449737 18962892, 19187515, 19513888, 19230771, 19853036, 19453778, 19551830 19068333, 18520351, 18843572, 19185148, 18945435, 19232454, 18541110 18834955, 19319192, 19204743, 19178629, 19304104, 19140891, 19270660 19457575, 19021575, 19069755, 18715884, 19584688, 18798573, 19812592 19018001, 19325701, 19292272, 19270956, 19222693, 18700893, 19662663 18406774, 19010177, 18910576, 18907170, 19700294, 19164099, 19331454 18955644, 18508710, 18798432, 19146822, 19589221, 19537762, 16286734 18762843, 19045143, 18945249, 19146980, 19184799, 19205086, 20091753 18862203, 19537547, 19281106, 19031737, 19079087, 18968981, 19148367 19150517, 20231741, 19217019, 18730096, 18975620, 19205617, 19513351 18843054, 19150313, 18708349, 18953639, 19067804, 19371270, 19203996 20038431, 19054979, 19209951, 19318983, 19154673, 18752378, 19150088 19013444, 19234177, 18998379, 20157569, 18999857, 19273577, 19075747 19367276, 19632437, 19612597, 19874047, 19288396, 18990354, 19557558 19427050, 19127078, 18910443, 20053557, 20033787, 19315567, 19148982 18290252, 18813323, 19777496, 19500293, 18643483, 19277814, 18523468 19134098, 19071526, 18965694, 19226858, 18850051, 19602208, 20061168 18417590, 19370739, 18920408, 19609388, 18636884, 18776786, 18989446 19148793, 19043795, 19585454, 19955755, 18317489, 18260170, 18919682 19807548, 18678829, 19124972, 19147509, 18849896, 18910748, 19273758 18953878, 19076165, 19704993, 18999195, 19498411, 18759724, 19459023 20276459, 19066844, 17208793, 19234907, 13843841, 19538714, 19383028 19649640, 19062675, 19513969, 18859710, 19504641, 19341481, 20293730 19986391, 18304090, 19343245, 19314048, 18834934, 19473851, 19241655 18242738, 19458082, 19470791, 18894342, 18372060, 19522067, 18953889 18827679, 19259290, 19140711, 19023430, 19045388, 19241857, 19076778 19522571, 18875012, 18861564, 19066699, 19273760, 19225265, 18819158 19068003, 18937186, 19049721, 19368917, 19635215, 18868829, 19141785 19885321, 19163887, 19820247, 18715868, 18852058, 19538241, 19804032 |
Rac system comprising of multiple nodes
Local node = XXXDB01
Remote node = XXXDB02
——————————————————————————–
OPatch succeeded.
- Patch 적용
- Patch 적용 전 적용되는 제품(Clusterware, Database, Listener)은 종료한다.
- Download 받은 Patch File을 적당한 곳에 두고 압축을 푼다.
- 패치마다 적용 방법이 다르므로 README.txt 또는 README.html 파일의 지시에 따른다.
- RAC 의 경우 기본적으로 모든 노드에 동시에 적용되므로, 노드 각각에 따로 적용하는 경우 반드시 -local option을 사용한다.
- Patch 적용 확인 후 종료된 제품을 시작한다.
- Opatch 사용 방법 및 옵션 사항
| 명령어 | 설 명 |
| opatch apply | 현재 디렉토리의 Patch 적용 RAC의 경우 모든 노드에 적용 |
| opatch apply -local | 현재 디렉토리의 Patch 를 현재 노드에 적용 |
| opatch apply -invPtrLoc | Oracle Inventory를 직접 지정하여 설치하는 경우 |
| opatch lsinventory –oh /oracle/product/11.2.0 | /oracle/product/11.2.0/db 에 적용된 Patch 표시 |
| opatch lsinventory –all | 현재 노드에 적용된 모든 Patch 표시 |
| opatch rollback -id patch# | 적용된 Patch 복구 |
| opatch rollback -id patch# -local | 현재 노드에 적용된 Patch 복구 |
-
Oracle Database Parameter 변경 관리oracle Database의 Parameter의 설정 값에 따라 system에 미치는 영향이 다양하다. 이에 충분한 검토가 사전에 필요하며, 관련 팀과의 협조가 필요한 부분에 대해서는 조율을 통해 조정토록 한다. Parameter변경은 변경 이력 관리를 통해 사후에 조정될 항목을 미리 점검해 보며, 문제점과 위험성을 도출해 사전 제거토록 한다.
-
Parameter 변경 Process
-
Parameter 변경 방법XXXDB Database는 SPFile (Server Parameter File) 를 사용하므로 Parameter 변경 시 SQL*Plus 를 사용해야 한다.
-

| alter system [SET|RESET] NAME=VALUE scope=[MEMORY|SPFILE|BOTH] sid=[‘*’|’SID’]; [SET|RESET] SET : Parameter 값 설정 RESET : Parameter 값을 Default로 설정. scope=[MEMORY|SPFILE|BOTH] MEMORY : 현재 기동중인 Instance 에서만 적용. Restart후 원래 값으로 복원 SPFILE : 현재 Instance 에는 적용하지 않고 SPFile 에만 적용. Restart후 적용 BOTH : Memory, SPfile 모두에 적용 sid=[‘*’|’SID’] : Single Instance 에서는 sid 값을 생략해도 된다. ‘*’ : RAC의 경우 모든 Instance 에 적용 ‘SID’ : 해당 SID 에 적용 |
- 주요 Parameter
| 구분 | Parameter | 설정 값 | 설명 |
| Archive | log_archive_dest_1 | LOCATION=/ARCH | archive log file 이 저장될 위치 |
| log_archive_format | ORAPTL%t_%s_%r.arc | archive log file 형식 지정 | |
| Cluster Database |
cluster_database | TRUE | RAC DB 구성 여부 |
| cluster_database_instance | 2 | Instance 개수 | |
| thread | 1, 2 | Thread 번호 | |
| instance_number | 1, 2 | Instance 번호 | |
| SGA/PGA Memory |
db_cache_size | 5G | DB Buffer Cache 크기 |
| shared_pool_size | 2G | Shared Pool 크기 | |
| java_pool_size | 200M | Java Pool 크기 | |
| large_pool_size | 200M | Large Pool 크기 | |
| pga_aggregate_target | 10G | PGA 영역 크기 | |
| Process and Session |
processes | 2000 | 사용 가능한 최대 process 개수 |
| sessions | 3040 | Default 로 (processes*1.5)+22 로 자동 산정됨 |
|
| open_cursors | 300 | Open 가능한 최대 Cursor 개수 | |
| ETC | audit_trail | NONE | DB 감사기능 설정 여부 |
| sec_case_sensitive_logon | FALSE | password 대소문자 구분 지정 | |
| deferred_segment_creation | FALSE | segment 생성시 지연된 공간 할당설정 |
- Parameter 적용 예제
| OS>sqlplus “/as sysdba” — Instance가 기동 중일 동안 SGA Size를 3G 로 변경. SQL> alter system set SGA_TARGET=3G scope=MEMORY; System altered. — SPFile 에만 SGA Size를 3G 로 변경. SQL>alter system set SGA_TARGET=3G scope=SPFILE; — Instance, SPFile 모두 PARALLEL_MIN_SERVERS 를 6으로 변경. SQL>alter system set PARALLEL_MIN_SERVERS=6 scope=BOTH; — Instance 에서 SPFile 에만 OPEN_CURSORS 를 초기화 SQL>alter system reset OPEN_CURSORS scope=SPFILE; — SPFile 설정값 확인 SQL> select * from v$spparameter where isspecified=’TRUE’; — 현재의 Parameter 값 확인 SQL> select * from v$parameter where isdefault = ‘FALSE’; |
-
Oracle 로그 파일 관리
-
ADR(Automatic Diagnostic Repository)11g의 새로운 기능으로 ADR(Automatic Diagnostic Repository)이라는 concept으로 관리 되며 ADR은 기존에 BDUMP와 UDUMP로 나뉘어 관리되던 것을 한 곳에 모아 관리하고 손쉽게 Oracle Support에 그 Data를 전달할 수 있다.
- ADR 관련 Parameter
- ADR 관련 Parameter
-
| $ sqlplus “/as sysdba” SQL> show parameter diagnostic_dest NAME TYPE VALUE ———————————— ———– —————————— diagnostic_dest string /oracle/base |
- ADR 관련 로그 확인
Oracle Database 및 listener 로그는 자동으로 삭제되지 않는다. 따라서 주기적으로 복사 후 삭제가 필요하다. Database에서 문제 발생시 또는 Action에 대한 Log는 중요한 역할을 하기 때문에 일정기간 보관 후 삭제한다.
| 로그 위치 | Directory | Description | |||
| /oracle/base/diag/rdbms/<SID>/<SID>/ | alert | xml형식의 alert log (log.xml)가 저장된다. | |||
| cdump | core dump 파일이 저장된다. | ||||
| trace | background and server process trace files와 SQL trace files, 그리고 text형식의 alert_SID.log가 저장된다. | ||||
| incpkg | incident packages가 저장된다. | ||||
| hm | health monitor reports가 저장된다. | ||||
| /grid/base/diag/tnslsnr/<hostname>/listener/ | trace | Listener 관련 로그 (listener.log) |
- CRS 관련 로그
| 로그 위치 | Directory | Description | |||
| /grid/12.1.0.2/log/<hostname> | crsd | crs daemon이 활동한 로그가 저장된다. | |||
| cssd | css daemon이 활동한 로그가 저장된다. | ||||
| evmd | evm daemon이 활동한 로그가 저장된다. |
-
백업과 복구
-
백업 개요오라클은 다양한 백업(Back-up) 기능을 제공한다. 오라클은 백업의 형태에 따라 데이터베이스가 붕괴된 시점까지도 복구할 수 있다. 그러나, 오라클을 복구하는 과정에서 기본이 되는 것은 데이터베이스 백업(Backup) 이다. 즉, 데이터베이스의 일관성 있는 백업이 선행되어야 오라클 복구(Recovery) 작업도 수월하게 이루어질 수 있다.
오라클은 ARCHIVELOG 모드이냐 NOARCHIVELOG 모드로 운영되느냐에 따라 백업의 형태가 달라지며 백업 정책도 달라진다. 각 모드마다 장단점이 있지만 ARCHIVE 모드가 물론 더 안정적이다.
Oracle ASM 환경에서의 Online Backup은 RMAN으로만 가능하므로 RMAN 기능에 대한 내용은 10장에 소개하고, Export/Import 에 대한 내용은 다음과 같다.Offline Backup Online Backup Export Datafile 과의 관계 Database를 구성하는 Datafile들을 논리적인 내용과는 무관하게 복사하는 방법 물리적인 위치와 무관하게 Database내용을 읽어서 file(dump)에 기록하는 방법 DBMS 운영 방법 Archive모드, Noarchive모드로 운영가능 Archive모드 운영 시만 가능 Archive모드, Noarchive모드로 운영가능 DBMS 기동 상태 DBMS 정상 정지 후 사용가능 DBMS 운영 중에만 사용가능 DBMS 운영 중에만 사용가능 Archive 모드로 운영 시 장애 발생시점까지 복구 가능 장애 발생시점까지 복구 가능 Export 받은 시점까지만 복구 가능 Noarchive 모드로 운영 시 Cold Backup, 받은 시점까지만 복구가능 적용 불가능 Export 받은 시점까지만 복구 가능 - 오라클에서 제공하는 백업의 종류는 다음과 같다.
- 데이터베이스를 구축한다는 것은 하나의 데이터를 여러 유저가 공유하기 위함도 있지만 무엇보다도 데이터의 안정성이다. 만일의 사태가 발생하더라도 데이터의 손실을 막는 것에 목적이 있다.
-
Export / ImportExport 는 Database 에 저장된 내용을 file 형태의 O/S dump file 로 추출하는 tool이다. 반대로 import 는 export 로 받은 O/S Dump file 을 database 에 저장시키는 tool 이다.
- Export option
- Export option
- Export / Import 는 모든 user 들의 전체 backup 이나 user 단위, 또는 특정 object만 backup 할 수 있으므로 database 의 backup 은 물론, Oracle database 간의 data 이동이나, Oracle 의 새로운 version upgrade 등에 사용될 수 있으며 문제발생시 특정 object 별 복구가 가능하다는 장점이 있는 반면에, database 복구 시, 물리적인 backup ( cold backup, hot backup ) 과 상호 관련성이 없기 때문에 장애 발생 시점까지의 복구는 불가능하며, 단지 export 를 수행한 시점까지의 복구만이 가능하기 때문에 export 를 이용한 복구는 data 의 손실을 감안하여야 한다는 단점이 있다.
-
| 옵션 | 내용 |
| userid | 유저명과 패스워드를 쓴다. |
| file | export 받는 덤프 파일을 지정한다. |
| log | export 받을 때 로그 파일을 지정한다. |
| rows | 데이터를 받을 것인지 아닌지를 지정한다. |
| constraints | 테이블의 제약 조건을 받을 것인지 지정한다. |
| indexes | 인덱스를 받을 것인지를 지정한다. |
| tables | 유저의 특정 테이블을 받고자 할 때 사용된다. |
| compress | 테이블을 위해 EXTENT 된 값이 Storage 값의 INITIAL 값에 설정된다. |
| full | userid 가 system이거나 dba 권한이 있는 유저일 경우에만 설정 가능하며, 데이터베이스 전체를 받고자 할 때 사용된다. |
- Import option
| 옵션 | 내용 |
| userid | 유저명과 패스워드를 쓴다. |
| file | export 받은 덤프 파일을 지정한다. |
| log | import 할 때 로그 파일을 지정한다. |
| rows | 데이터를 삽입 할 것인지 아닌지를 지정한다. |
| constraints | 테이블의 제약 조건을 넣을 것인지 지정한다. |
| indexes | 인덱스를 생성 할 것인지를 지정한다. |
| tables | 유저의 특정 테이블을 지정하여 삽입 할 때 사용된다. |
| indexfile | 데이터를 import하지 않고 create index 문장의 SQL로 파일이 만들어진다. |
| fromuser | 다른 유저에게 export 한 파일을 import 하고자 할 때 export 한 유저를 지정한다. |
| touser | import 할 유저를 지정한다. |
- Export / Import example
- Export example
| 옵션 | 내용 |
| Database 전체 | $exp system/manager file=/backup/full_exp.dmp log=/backup/full_exp.log full=y |
| User 단위 | $exp system/manager file=/backup/scott.dmp log=/backup/scott.log owner=scott |
| Table 단위 | $exp system/manager file=/backup/scott_emp.dmp log=/backup/scott_emp.log tables=scott.emp |
- Import example
| 옵션 | 내용 |
| Database 전체 | $imp system/manager file=/backup/full_exp.dmp log=/backup/full_imp.log full=y |
| User 단위 | $imp system/manager file=/backup/scott.dmp log=/backup/scott_imp.log fromuser=scott touser=hr |
| Table 단위 | $imp system/manager file=/backup/scott_emp.dmp log=/backup/scott_emp_imp.log tables=scott.emp |
-
Recovery Manager(RMAN)
-
RMAN 구조
- RMAN의 기본 개요
- RMAN의 특징
- RMAN의 기본 개요
-
- DB 전체, Tablespace단위, Database files, Archive logs, 그리고 Control files등 Backup이 자주 실행되는 명령들은 script로 저장하여 간단하게 실행할 수 있다.
- Incremental block level backup을 할 수 있다.
- 사용되어지지 않은 database block들은 skip한다.
- Backup / restore 시 각 block 에 대한 checksum 을 통해 Corrupted block 을 발견한다.
- Tablespace를 Online으로 백업 할 때, tablespace를 backup mode 로 변경 할 필요가 없다.
- Backup performance를 향상 시킨다. (Parallelization, less redo log 생성)
- OS 의 open file limit 을 피하기 위해 open file limit 을 지정할 수 있으며, 백업 사이즈의 limit 을 줄 수 있다.
- RMAN Architecture
관리자가 RMAN 유틸리티에게 백업이나 복구를 명령하면 RMAN유틸리티는 관리자를 대신하여 대상 서버 (Target Database)에 접속하여 Server Process에게 백업을 수행한다. 그리고 관련 정보를 Recovery Catalog Server가 있으면 Catalog Database에 저장하고, 만약 없다면 Target Database의 Control file에 기록한다.
RMAN은 서버 쪽의 SID를 체크하고 sys 사용자로 로그인 하게 된다. 그리고 인스턴스에 접속하기 위해 Channel Server Process를 생성하게 된다. Channel Server Process의 기본값은 1개다. 이 Server Process가 사용 할 PGA가 할당된다.
이 패키지는 Control file의 정보를 읽어서 데이터베이스 전체 의 파일들에 관한 정보와 체크포인트 정보, 생성 시간 정보, 각 Data file의 온라인/오프라인 정보 및 위치 정보들을 모으게 된다. 이렇게 정보를 모은 후 본격적인 백업 작업을 수행하기 전에 백업되는 동안 변경되는 정보들로부터 현재 시점의 정보를 지키기 위해 Control file을 스냅샷 해서 보관하게 된다.
이 후 DBMS_BACKUP_RESTORE 패키지를 호출하여 정해진 위치에 백업 피스를 만든다. 모든 백업 파일이 백업 피스에 저장 완료되면 RMAN은 다시 DBMS_BACKUP_RESTORE 패키지를 호출해서 백업 피스의 이름과 시간 마지막 체크포인트 정보 등을 Control file에 기록한다. 이 과정까지 끝나면 백업이 완료된다.
- Recovery Catalog
Recovery Catalog란 RMAN 사용 시 에 RMAN으로 백업 복구 작업을 하고 관련 정보를 저장해 두는 저장소이다. Recovery Catalog Server가 없을 경우 RMAN은 Target Database Server의 control file에 해당 정보를 저장하고 Recovery Catalog Server가 있을 경우 Recovery Catalog Server에 정보를 저장한다.
Recovery Catalog에 저장되는 정보는 아래와 같다.
- Data file, Archive file 및 Redo log file의 백업 셋과 copy 된 이미지에 대한 정보
- 백업 대상서버의 물리적인 구조
- 자주 사용하는 백업 스크립트 (Recovery Catalog Server를 사용할 경우만 해당)
-
RMAN 명령어
- RMAN 접속
ORACLE USER로 수행 한다. - RMAN 접속
- 차이점은 RMAN은 SYSDBA 권한을 가지고 타겟과 보조 데이터베이스에 접속해야 하는데 AS SYSDBA 키워드는 사용하지 않아도 묵시적으로 가진 것으로 접속이 가능하다.
| [oracle@XXXDB01 ~]$ rman target / Recovery Manager: Release 12.1.0.2.0 – Production on Thu Jun 11 10:00:31 2015 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. connected to target database: XXXDB (DBID=611517755) RMAN> |
- RMAN CONFIGURE COMMAND
configure의 설정된 환경 값을 바르게 설정되어 있는 경우, 간단하게 BACKUP DATABASE; 문을 실행하여 데이터베이스를 백업할 수 있다.
RMAN이 백업과 복구를 실행하는 구성을 미리 작성한 디폴트 configure가 준비되어 적용된다. 또한 CONFIGURE 명령으로 channel parameter를 재 작성할 수 있다.
- Default RMAN configuration
Show all 명령어를 사용하면, default configuration 값을 확인 할 수 있다.
| RMAN> show all; using target database control file instead of recovery catalog RMAN configuration parameters for database with db_unique_name XXXDB are: CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # default CONFIGURE BACKUP OPTIMIZATION OFF; # default CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default CONFIGURE CONTROLFILE AUTOBACKUP OFF; # default CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO ‘%F’; # default CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; # default CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default CONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE DISK TO 1; # default CONFIGURE MAXSETSIZE TO UNLIMITED; # default CONFIGURE ENCRYPTION FOR DATABASE OFF; # default CONFIGURE ENCRYPTION ALGORITHM ‘AES128’; # default CONFIGURE COMPRESSION ALGORITHM ‘BASIC’ AS OF RELEASE ‘DEFAULT’ OPTIMIZE FOR LOAD TRUE ; # default CONFIGURE RMAN OUTPUT TO KEEP FOR 7 DAYS; # default CONFIGURE ARCHIVELOG DELETION POLICY TO NONE; # default CONFIGURE SNAPSHOT CONTROLFILE NAME TO ‘/oracle/12.1.0.2/dbs/snapcf_JCDB1.f’; # default |
주요 configuration 수정 하는 방법은 다음과 같다.
| RMAN> CONFIGURE RETENTION POLICY TO RECOVERY WINDOW OF 1 DAYS; à 이 파라미터는 복구에 사용할 백업 파일의 보존 기간을 설정하는 것으로 1DAYS 하면 1일치만 복구하기 위해 보존한다는 의미이다. 이 정책을 넘어선, 즉 1일이 지난 백업 파일을 모두 지우려면 DELETE OBSOLETE 명령어를 시용하면 된다. RMAN> CONFIGURE RETENTION POLICY TO REDUNDANCY 1; à 이 명령어는 백업본의 개수를 지정한다. 만일의 경우 백업 파일이 손상될 수 있기 때문에 REDUNDANCY 숫자만큼 백업 파일을 다중화해서 생성하라는 의미이다. 여기서는 1개로 지정한 내용이다. RMAN> CONFIGURE DEVICE TYPE DISK PARALLELISM 2; à 이 설정은 기본 Channel에 백업을 받을 때 백업 수행 프로세스의 병렬도를 설정하는 것이다. 이 예처럼 설정하면 기본 Channel로 백업 받을 때 백업 프로세스가 2개 생성되어 백업을 동시에 진행할 것이다. RMAN> CONFIGURE DEFAULT DEVICE TYPE TO DISK à default backup device를 설정한다. RMAN> CONFIGURE CONTROLFILE AUTOBACKUP ON; à RMAN의 BACKUP이나 COPY 명령들의 수행 후 자동으로 control file backup을 수행한다. RMAN> CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO ‘%F’; à autobackup되는 control file의 기본 format을 변경한다. RMAN> CONFIGURE DATAFILE BACKUP COPIES FOR DEVICE TYPE DISK TO 1; à datafile, control file의 backup set의 copy본 개수를 지정한다. RMAN> CONFIGURE ARCHIVELOG BACKUP COPIES FOR DEVICE TYPE DISK TO 1; à archivelog file의 backup set의 copy본 개수를 지정한다. RMAN> CONFIGURE MAXSETSIZE TO UNLIMITED; à 해당 Channel에서 백업 받아지는 백업셋의 최대 크기를 UNLIMITED로 설정하는 명령어다. RMAN> CONFIGURE BACKUP OPTIMIZATION ON; à 이 설정은 만약 백업 받는 경로에 같은 백업 파일이 존재하면 그 파일은 백업 받지 말고 넘어가라는 의미이다. RMAN은 해당 백업 파일이 같은 파일인지 구별하기 위해 백업되어 있는 파일과 지금 백업하려는 파일의 DBID, Checkpoint SCN, Creation SCN, Resetlogs SCN and time을 서로 비교해서 모든 것 이 완벽하게 맞으면 동일 파일로 인정하게 Skip 한다. 기본값은 OFF RMAN> CONFIGURE CHANNEL DEVICE TYPE DISK MAXPIECESIZE 50M; à 이 설정은 해당 Channel로 백업 받을 때 백업 파일 하나의 최대 크기를 지정하는 명령어 이다. |
- Default configuration 변경
만약 default device type을 변경하려면 다음과 같이 변경 하면 된다. 이 외의 다른 configuration 변경도 아래 step 과 동일하다.
| RMAN> show default device type; RMAN configuration parameters for database with db_unique_name XXXDB are: CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default RMAN> CONFIGURE DEFAULT DEVICE TYPE TO SBT; old RMAN configuration parameters: CONFIGURE DEFAULT DEVICE TYPE TO DISK; new RMAN configuration parameters: CONFIGURE DEFAULT DEVICE TYPE TO ‘SBT_TAPE’; new RMAN configuration parameters are successfully stored RMAN> show default device type; RMAN configuration parameters for database with db_unique_name XXXDB are: CONFIGURE DEFAULT DEVICE TYPE TO ‘SBT_TAPE’; |
- SHOW 명령어
Show all 명령어를 사용하면 configuration 값을 모두 사용 할 수 있다. 특정 한 것을 볼 경우 아래와 같이 사용 하면 된다.
| RMAN> show default device type; RMAN configuration parameters for database with db_unique_name XXXDB are: CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default à 변경하지 않은 configuration은 # default 라고 표시 된다. RMAN> show default device type; RMAN configuration parameters for database with db_unique_name XXXDB are: CONFIGURE DEFAULT DEVICE TYPE TO DISK; à 변경이 된 configuration은 # default가 사라지며 해당 configuration 값이 나타난다. |
- LIST 명령어
- LIST DATABASE
| RMAN> list backup of database; List of Backup Sets =================== BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 1 Full 467.06M DISK 00:00:18 11-JUN-15 BP Key: 1 Status: AVAILABLE Compressed: NO Tag: TAG20150611T111129 Piece Name: /oracle/12.1.0.2/dbs/01q97fn1_1_1 List of Datafiles in backup set 1 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 1 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/system01.dbf 2 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/sysaux01.dbf 3 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/undotbs101.dbf 4 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/undotbs201.dbf 5 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/users01.dbf |
- LIST BACKUP OF DATAFILE
| RMAN> list backup of datafile ‘+DG_DATA/XXXDB/system01.dbf’; List of Backup Sets =================== BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 1 Full 467.06M DISK 00:00:18 11-JUN-15 BP Key: 1 Status: AVAILABLE Compressed: NO Tag: TAG20150611T111129 Piece Name: /oracle/12.1.0.2/dbs/01q97fn1_1_1 List of Datafiles in backup set 1 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 1 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/system01.dbf |
- LIST BACKUP
| RMAN> list backup; List of Backup Sets =================== BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 1 Full 467.06M DISK 00:00:18 11-JUN-15 BP Key: 1 Status: AVAILABLE Compressed: NO Tag: TAG20150611T111129 Piece Name: /oracle/12.1.0.2/dbs/01q97fn1_1_1 List of Datafiles in backup set 1 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 1 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/system01.dbf 2 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/sysaux01.dbf 3 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/undotbs101.dbf 4 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/undotbs201.dbf 5 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/users01.dbf BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 2 Full 18.11M DISK 00:00:04 11-JUN-15 BP Key: 2 Status: AVAILABLE Compressed: NO Tag: TAG20150611T111156 Piece Name: /oracle/12.1.0.2/dbs/c-611517755-20150611-00 Control File Included: Ckp SCN: 1184594 Ckp time: 11-JUN-15 |
-
Channel 할당하기Channel이란 쉽게 말하면 백업과 복구를 하는 경로를 의미한다. 백업을 수행하기 전에 Channel을 할당해주어야 RMAN이 백업/복구를 수행할 수 있다. 복구할 때는 Channel을 할당하지 않아도 되지만 백업할 경우는 반드시 Channel을 할당해 주어야 한다. Channel을 할당하는 방법은 자동 Channel 설정 과 수동 Channel 설정이 있다.
- 자동 Channel 할당하기
- 자동 Channel 할당하기
- RMAN 접속
| [oracle@XXXDB01 ~]$ rman target / Recovery Manager: Release 12.1.0.2.0 – Production on Fri Jun 12 03:41:41 2015 Copyright (c) 1982, 2014, Oracle and/or its affiliates. All rights reserved. connected to target database: XXXDB (DBID=611517755) |
- 자동 Channel 설정
아래와 같이 설정하면 default device가 파라미터 파일의 db_recovery_file_dest 파라미터 경로로 설정되며 해당 파라미터가 설정되어 있지 않다면 $ORACLE_HOME/dbs에 저장된다.
| RMAN> configure default device type to disk; using target database control file instead of recovery catalog old RMAN configuration parameters: CONFIGURE DEFAULT DEVICE TYPE TO DISK; new RMAN configuration parameters: CONFIGURE DEFAULT DEVICE TYPE TO DISK; new RMAN configuration parameters are successfully stored |
- 자동 Channel 경로 변경
/u01/app/backup 경로를 default device로 설정한다. 즉 앞으로 특별한 경로 없이 백업을 수행하면 이곳에 백업이 생성된다. %U(대문자 U) 는 파일명이 중복되지 않도록 RMAN 이 Unique 한 번호로 파일 이름을 생성하면서 백업을 수행하라는 의미이며 %T는 백업 날짜를 표시 하라는 뜻이다.
| RMAN> configure channel device type disk 2> format ‘/u01/app/backup/%U_%T’; new RMAN configuration parameters: CONFIGURE CHANNEL DEVICE TYPE DISK FORMAT ‘/u01/app/backup/%U_%T’; new RMAN configuration parameters are successfully stored |
- 자동 Channel 경로 변경 TEST
| RMAN> backup tablespace users; à경로 지정 없이 백업을 수행 시킴. Starting backup at 12-JUN-15 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=42 instance=XXXDB1 device type=DISK channel ORA_DISK_1: starting full datafile backup set channel ORA_DISK_1: specifying datafile(s) in backup set input datafile file number=00005 name=+DG_DATA/XXXDB/users01.dbf channel ORA_DISK_1: starting piece 1 at 12-JUN-15 channel ORA_DISK_1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/05q99aih_1_1_20150612 tag=TAG20150612T035601 comment=NONE à/oracle/backup 경로에 백업 파일이 생성 된 것을 확인 할 수 있다. channel ORA_DISK_1: backup set complete, elapsed time: 00:00:01 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-01 comment=NONE Finished Control File Autobackup at 12-JUN-15 |
- 수동 Channel 할당 하기
수동 Channel이란 백업을 수행할 때 백업 받을 경로를 지정해 주는 것이다. 아래 방법은 작업형 명령어를 사용하여 수동 Channel을 할당하는 것이다. /oracle/backup/manual 경로에 백업 파일이 생성 된다.
| RMAN> run { 2> allocate channel c1 type disk 3> format ‘/oracle/backup/manual/%U_%T’; 4> backup tablespace users; 5> } allocated channel: c1 channel c1: SID=42 instance=XXXDB1 device type=DISK Starting backup at 12-JUN-15 channel c1: starting full datafile backup set channel c1: specifying datafile(s) in backup set input datafile file number=00005 name=+DG_DATA/XXXDB/users01.dbf channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/manual/0aq99b12_1_1_20150612 tag=TAG20150612T040346 comment=NONE channel c1: backup set complete, elapsed time: 00:00:01 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-03 comment=NONE Finished Control File |
또는 아래와 같이 독립형 명렁어로도 가능하다.
| RMAN> backup tablespace users format ‘/oracle/backup/manual/%U_%T’; Starting backup at 12-JUN-15 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=42 instance=XXXDB1 device type=DISK channel ORA_DISK_1: starting full datafile backup set channel ORA_DISK_1: specifying datafile(s) in backup set input datafile file number=00005 name=+DG_DATA/XXXDB/users01.dbf channel ORA_DISK_1: starting piece 1 at 12-JUN-15 channel ORA_DISK_1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/manual/0cq99b6r_1_1_20150612 tag=TAG20150612T040651 comment=NONE channel ORA_DISK_1: backup set complete, elapsed time: 00:00:01 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-04 comment=NONE Finished Control File Autobackup at 12-JUN-15 |
- Channel 할당 정리
자동 Channel 할당보다 수동 Channel 할당이 더 우선적으로 적용 된다. 그리고 수동 Channel을 사용하면 RMAN은 해당 경로에 받는 백업 파일을 관리하지 않는다. 이 말의 의미는 Retention Policy 등이 설정되어 있더라도 format 파라미터를 사용해서 경로를 변경하면 해당 정책들이 적용 안 된다는 것을 의미 한다. FRA에 저장한다 하더라도 format 파라미터로 경로가 정해지면 관리자가 수동으로 백업 파일을 관리 해야만 한다.
-
RMAN BACKUPRMAN의 BACKUP 방법은 독립형 명령어(standalone)으로 백업 받기와 작업형 명령으로 백업 받기 가 있다. 독립형 명령어는 한 개의 명령어가 수행되는 것을 말하며, 작업형 명령어는 마치 프로그램의 스크립트처럼 여러 개의 명령어를 한꺼번에 사용하는 방법이다. 앞으로 예제는 작업형 명령어로 수행 하겠다.
- Database full backup
- Database full backup
- Database full backup 수행
/oracle/backup 경로에 백업 파일을 생성하며, database full 백업을 수행한다. List backup으로 확인 했을 때 tag는 구분 하기 쉽게 FULL_DB로 보여 지게 된다.
| RMAN> run { 2> # backup the complete database to disk 3> allocate channel c1 type disk; 4> backup 5> full 6> tag full_db 7> format ‘/oracle/backup/db_%U_%T’ 8> (database); 9> release channel c1; 10> } released channel: ORA_DISK_1 allocated channel: c1 channel c1: SID=42 instance=XXXDB1 device type=DISK Starting backup at 12-JUN-15 channel c1: starting full datafile backup set channel c1: specifying datafile(s) in backup set input datafile file number=00001 name=+DG_DATA/XXXDB/system01.dbf input datafile file number=00002 name=+DG_DATA/XXXDB/sysaux01.dbf input datafile file number=00003 name=+DG_DATA/XXXDB/undotbs101.dbf input datafile file number=00004 name=+DG_DATA/XXXDB/undotbs201.dbf input datafile file number=00005 name=+DG_DATA/XXXDB/users01.dbf channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/db_0eq99c4i_1_1_20150612 tag=FULL_DB comment=NONE channel c1: backup set complete, elapsed time: 00:00:25 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-05 comment=NONE Finished Control File Autobackup at 12-JUN-15 released channel: c1 |
- Database full backup 확인
경로 및 Tag에 위에서 수행한 내용이 나타나 있다.
| RMAN> list backupset of database; List of Backup Sets =================== BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 11 Full 508.86M DISK 00:00:24 12-JUN-15 BP Key: 11 Status: AVAILABLE Compressed: NO Tag: FULL_DB Piece Name: /oracle/backup/db_0eq99c4i_1_1_20150612 List of Datafiles in backup set 11 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 1 Full 1291744 12-JUN-15 +DG_DATA/XXXDB/system01.dbf 2 Full 1291744 12-JUN-15 +DG_DATA/XXXDB/sysaux01.dbf 3 Full 1291744 12-JUN-15 +DG_DATA/XXXDB/undotbs101.dbf 4 Full 1291744 12-JUN-15 +DG_DATA/XXXDB/undotbs201.dbf 5 Full 1291744 12-JUN-15 +DG_DATA/XXXDB/users01.dbf |
- Tablespace backup
Tablespace 별로 백업 받을 때 사용 할 수 있다.
- Tablespace backup 수행
아래 예제는 USERS TABLESPACE와 SYSAUX TABLESPACE의 백업 수행 내용 이다.
/oracle/backup 경로에 백업 파일이 생성 된다.
| RMAN> run { 2> allocate channel c1 type disk; 3> backup 4> tag tbs_users_sysaux 5> format ‘/oracle/backup/tbs_%U_%T’ 6> (tablespace users, sysaux); 7> release channel c1; 8> } allocated channel: c1 channel c1: SID=42 instance=XXXDB1 device type=DISK Starting backup at 12-JUN-15 channel c1: starting full datafile backup set channel c1: specifying datafile(s) in backup set input datafile file number=00002 name=+DG_DATA/XXXDB/sysaux01.dbf input datafile file number=00005 name=+DG_DATA/XXXDB/users01.dbf channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/tbs_0gq99cp3_1_1_20150612 tag=TBS_USERS_SYSAUX comment=NONE channel c1: backup set complete, elapsed time: 00:00:07 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-06 comment=NONE Finished Control File Autobackup at 12-JUN-15 released channel: c1 |
- Tablespace backup 확인
위에서 개별적으로 백업 받은 내용뿐만 아니라, FULL BACKUP 받았던 내용까지 나온다. FULL BACKUP 내역에 해당 테이블 스페이스가 존재 하기 때문이다.
| RMAN> list backupset of tablespace sysaux; List of Backup Sets =================== BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 1 Full 467.06M DISK 00:00:18 11-JUN-15 BP Key: 1 Status: AVAILABLE Compressed: NO Tag: TAG20150611T111129 Piece Name: /oracle/12.1.0.2/dbs/01q97fn1_1_1 List of Datafiles in backup set 1 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 2 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/sysaux01.dbf BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 11 Full 508.86M DISK 00:00:24 12-JUN-15 BP Key: 11 Status: AVAILABLE Compressed: NO Tag: FULL_DB Piece Name: /oracle/backup/db_0eq99c4i_1_1_20150612 List of Datafiles in backup set 11 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 2 Full 1291744 12-JUN-15 +DG_DATA/XXXDB/sysaux01.dbf BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 13 Full 194.69M DISK 00:00:04 12-JUN-15 BP Key: 13 Status: AVAILABLE Compressed: NO Tag: TBS_USERS_SYSAUX Piece Name: /oracle/backup/tbs_0gq99cp3_1_1_20150612 List of Datafiles in backup set 13 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 2 Full 1292370 12-JUN-15 +DG_DATA/XXXDB/sysaux01.dbf |
- Datafile backup
Datafile 별로 백업 받을 때 사용 할 수 있다.
- Datafile 확인
Report schema를 확인 한다. 현재 datafile 및 tempfile을 알 수 있다.
| RMAN> report schema; Report of database schema for database with db_unique_name XXXDB List of Permanent Datafiles =========================== File Size(MB) Tablespace RB segs Datafile Name —- ——– ——————– ——- ———————— 1 700 SYSTEM YES +DG_DATA/XXXDB/system01.dbf 2 550 SYSAUX NO +DG_DATA/XXXDB/sysaux01.dbf 3 290 UNDOTBS1 YES +DG_DATA/XXXDB/undotbs101.dbf 4 200 UNDOTBS2 YES +DG_DATA/XXXDB/undotbs201.dbf 5 5 USERS NO +DG_DATA/XXXDB/users01.dbf List of Temporary Files ======================= File Size(MB) Tablespace Maxsize(MB) Tempfile Name —- ——– ——————– ———– ——————– 1 23 TEMP 32767 +DG_DATA/XXXDB/temp01.dbf |
- Datafile backup 수행
작업형 명령어로 아래와 같이 수행 할 수 있다.
| RMAN> run { 2> allocate channel c1 type disk; 3> backup 4> tag df_users 5> format ‘/oracle/backup/df_%U_%T’ 6> (datafile ‘+DG_DATA/XXXDB/users01.dbf’); 7> release channel c1; 8> } allocated channel: c1 channel c1: SID=39 instance=XXXDB1 device type=DISK Starting backup at 12-JUN-15 channel c1: starting full datafile backup set channel c1: specifying datafile(s) in backup set input datafile file number=00005 name=+DG_DATA/XXXDB/users01.dbf channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/df_0lq99hic_1_1_20150612 tag=DF_USERS comment=NONE channel c1: backup set complete, elapsed time: 00:00:01 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-08 comment=NONE Finished Control File Autobackup at 12-JUN-15 released channel: c1 |
또는 위에서 확인 한 report schema의 결과 내용을 보고 file number로 백업 받을 수도 있다.
| RMAN> run { 2> allocate channel c1 type disk; 3> backup 4> tag df_users2 5> format ‘/oracle/backup/df_%U_%T’ 6> (datafile 5); 7> release channel c1; 8> } allocated channel: c1 channel c1: SID=39 instance=XXXDB1 device type=DISK Starting backup at 12-JUN-15 channel c1: starting full datafile backup set channel c1: specifying datafile(s) in backup set input datafile file number=00005 name=+DG_DATA/XXXDB/users01.dbf channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/df_0nq99hu1_1_1_20150612 tag=DF_USERS2 comment=NONE channel c1: backup set complete, elapsed time: 00:00:01 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-09 comment=NONE Finished Control File Autobackup at 12-JUN-15 released channel: c1 |
- Datafile backup 확인
Datafile backup 내용 확인 같은 경우, 해당 datafile number를 적어 주어도 되고, 해당 datafile path를 적어 주어도 된다.
| RMAN> list backupset of datafile ‘+DG_DATA/XXXDB/users01.dbf’; RMAN> list backupset of datafile 5; List of Backup Sets =================== BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 17 Full 1.03M DISK 00:00:00 12-JUN-15 BP Key: 17 Status: AVAILABLE Compressed: NO Tag: DF_USERS Piece Name: /oracle/backup/df_0lq99hic_1_1_20150612 List of Datafiles in backup set 17 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 5 Full 1296675 12-JUN-15 +DG_DATA/XXXDB/users01.dbf BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 19 Full 1.03M DISK 00:00:00 12-JUN-15 BP Key: 19 Status: AVAILABLE Compressed: NO Tag: DF_USERS2 Piece Name: /oracle/backup/df_0nq99hu1_1_1_20150612 List of Datafiles in backup set 19 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 5 Full 1297097 12-JUN-15 +DG_DATA/XXXDB/users01.dbf |
- Control file backup
Controlfile backup 같은 경우에 수동으로 현재 control file을 백업 받을 수 있고, autobackup을 활성화 시켜, 데이터베이스 메타데이타가 변경될 대마다 자동 백업을 수행한다. 아래 예제는 수동으로 control file을 백업 받는 내용이다.
- Control file backup 수행
| RMAN> run { 2> allocate channel c1 type disk; 3> backup 4> tag control_bk 5> format ‘/oracle/backup/cf_%U_%T’ 6> (current controlfile); 7> release channel c1; 8> } allocated channel: c1 channel c1: SID=39 instance=XXXDB1 device type=DISK Starting backup at 12-JUN-15 channel c1: starting full datafile backup set channel c1: specifying datafile(s) in backup set including current control file in backup set channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/cf_0pq99ijk_1_1_20150612 tag=CONTROL_BK comment=NONE channel c1: backup set complete, elapsed time: 00:00:01 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-0a comment=NONE Finished Control File Autobackup at 12-JUN-15 released channel: c1 |
- Control file backup 확인
현재 해당 DB에는 CONTROLFILE AUTOBACKUP ON 으로 되어 있어, tag CONTRL_BK로 controlfile을 백업 했을 때, 같이 자동으로 controlfile이 backup 되었다.
| RMAN> list backup of controlfile; List of Backup Sets =================== BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 21 Full 18.11M DISK 00:00:03 12-JUN-15 BP Key: 21 Status: AVAILABLE Compressed: NO Tag: CONTROL_BK Piece Name: /oracle/backup/cf_0pq99ijk_1_1_20150612 Control File Included: Ckp SCN: 1298018 Ckp time: 12-JUN-15 BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 22 Full 18.11M DISK 00:00:02 12-JUN-15 BP Key: 22 Status: AVAILABLE Compressed: NO Tag: TAG20150612T061312 Piece Name: /oracle/12.1.0.2/dbs/c-611517755-20150612-0a Control File Included: Ckp SCN: 1298025 Ckp time: 12-JUN-15 |
- Archive log backup
Archive log 를 백업 받을 때 사용한다.
- Archive log 확인
현재 백업 받아져 있는 archive log 를 확인 한다. 현재 백업 받아져 있는 archive는 하나도 없다.
| RMAN> list backupset of archivelog all; specification does not match any backup in the repository |
- Archive log backup
작업형 명령어로 archive log를 백업 받을 수 있다.
| RMAN> run { 2> allocate channel c1 type disk; 3> backup 4> format ‘/oracle/backup/log_%U_%T’ 5> (archivelog all); 6> release channel c1; 7> } allocated channel: c1 channel c1: SID=39 instance=XXXDB1 device type=DISK Starting backup at 12-JUN-15 current log archived channel c1: starting archived log backup set channel c1: specifying archived log(s) in backup set input archived log thread=2 sequence=5 RECID=10 STAMP=882156427 input archived log thread=1 sequence=33 RECID=8 STAMP=882156427 input archived log thread=2 sequence=6 RECID=11 STAMP=882156428 input archived log thread=1 sequence=34 RECID=9 STAMP=882156427 channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/log_0rq99j1l_1_1_20150612 tag=TAG20150612T062035 comment=NONE channel c1: backup set complete, elapsed time: 00:00:03 channel c1: starting archived log backup set channel c1: specifying archived log(s) in backup set input archived log thread=1 sequence=1 RECID=12 STAMP=882166835 channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/log_0sq99j1o_1_1_20150612 tag=TAG20150612T062035 comment=NONE channel c1: backup set complete, elapsed time: 00:00:03 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-0b comment=NONE Finished Control File Autobackup at 12-JUN-15 released channel: c1 |
- Archive log backup 확인
RAC 이기 때문에 Thread 1,2 모두 백업 받아 진다.
| RMAN> list backupset of archivelog all; List of Backup Sets =================== BS Key Size Device Type Elapsed Time Completion Time ——- ———- ———– ———— ————— 23 17.53M DISK 00:00:00 12-JUN-15 BP Key: 23 Status: AVAILABLE Compressed: NO Tag:TAG20150612T062035 Piece Name: /oracle/backup/log_0rq99j1l_1_1_20150612 List of Archived Logs in backup set 23 Thrd Seq Low SCN Low Time Next SCN Next Time —- ——- ———- ——— ———- ——— 1 33 1175083 11-JUN-15 1285038 12-JUN-15 1 34 1285038 12-JUN-15 1287932 12-JUN-15 2 5 903151 03-JUN-15 1184015 11-JUN-15 2 6 1184015 11-JUN-15 1184017 11-JUN-15 BS Key Size Device Type Elapsed Time Completion Time ——- ———- ———– ———— ————— 24 11.98M DISK 00:00:01 12-JUN-15 BP Key: 24 Status: AVAILABLE Compressed: NO Tag:TAG20150612T062035 Piece Name: /oracle/backup/log_0sq99j1o_1_1_20150612 List of Archived Logs in backup set 24 Thrd Seq Low SCN Low Time Next SCN Next Time —- ——- ———- ——— ———- ——— 1 1 1287932 12-JUN-15 1298316 12-JUN-15 |
- 특정 범위의 Sequence Archive log backup
Archive log file을 전부 다 받는 것이 아니고, 특정 sequence의 범위를 줘서 백업 받을 수 있다. 아래 테스트는 1번 노드의 archive log file 중에 sequence 가 1부터 3번까지 백업 받는 내용 이다.
| RMAN> run { 2> allocate channel c1 type disk; 3> backup 4> tag log_1_3 5> format ‘/oracle/backup/log_%U_%T’ 6> (archivelog from sequence=1 until sequence=3 thread 1); 7> release channel c1; 8> } allocated channel: c1 channel c1: SID=39 instance=XXXDB1 device type=DISK Starting backup at 12-JUN-15 channel c1: starting archived log backup set channel c1: specifying archived log(s) in backup set input archived log thread=1 sequence=1 RECID=12 STAMP=882166835 input archived log thread=1 sequence=2 RECID=13 STAMP=882167494 input archived log thread=1 sequence=3 RECID=14 STAMP=882167497 channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/log_0uq99jnk_1_1_20150612 tag=LOG_1_3 comment=NONE channel c1: backup set complete, elapsed time: 00:00:01 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-0c comment=NONE Finished Control File Autobackup at 12-JUN-15 released channel: c1 |
- 특정 시간이 경과한 Archive log backup
Sequence 뿐만 아니라, 시간의 범위를 지정하여 백업 받을 수도 있다. 아래 예제는 하루 이내에 생성된 archive log들에 대해 백업 하는 내용이다. Backup 한 이후에 해당 archive log file을 삭제 한다.
| 구분 | 내용 |
| sysdate – 1 | 현재 날짜와 시간보다 1일전 |
| sysdate – 7 | 현재 날짜와 시간보다 7일전 |
| sysdate – 1/24 | 현재 날짜와 시간보다 1시간 전 |
| sysdate – 9/24 | 현재 날짜와 시간보다 9시간 전 |
| sysdate – 5/3600 | 현재 날짜와 시간보다 5분 전 |
| all delete input | Backup이 완료되면 삭제가 된다. 만일 Backup이 실패를 한다면 Archivelog 들은 지워지지 않는다. |
| RMAN> run { 2> allocate channel c1 type disk; 3> backup 4> tag log_oneday 5> format ‘/oracle/backup/log_%U_%T’ 6> (archivelog from time ‘sysdate-1’ all delete input); 7> release channel c1; 8> } allocated channel: c1 channel c1: SID=39 instance=XXXDB1 device type=DISK Starting backup at 12-JUN-15 current log archived channel c1: starting archived log backup set channel c1: specifying archived log(s) in backup set input archived log thread=2 sequence=5 RECID=10 STAMP=882156427 input archived log thread=1 sequence=33 RECID=8 STAMP=882156427 input archived log thread=2 sequence=6 RECID=11 STAMP=882156428 input archived log thread=1 sequence=34 RECID=9 STAMP=882156427 channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/log_10q99jv0_1_1_20150612 tag=LOG_ONEDAY comment=NONE channel c1: backup set complete, elapsed time: 00:00:03 channel c1: deleting archived log(s) archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_12/thread_2_seq_5.274.882156427 RECID=10 STAMP=882156427 archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_12/thread_1_seq_33.272.882156427 RECID=8 STAMP=882156427 archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_12/thread_2_seq_6.275.882156429 RECID=11 STAMP=882156428 archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_12/thread_1_seq_34.273.882156427 RECID=9 STAMP=882156427 channel c1: starting archived log backup set channel c1: specifying archived log(s) in backup set input archived log thread=1 sequence=1 RECID=12 STAMP=882166835 input archived log thread=1 sequence=2 RECID=13 STAMP=882167494 input archived log thread=1 sequence=3 RECID=14 STAMP=882167497 input archived log thread=1 sequence=4 RECID=15 STAMP=882167776 channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/log_11q99jv5_1_1_20150612 tag=LOG_ONEDAY comment=NONE channel c1: backup set complete, elapsed time: 00:00:01 channel c1: deleting archived log(s) archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_12/thread_1_seq_1.276.882166835 RECID=12 STAMP=882166835 archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_12/thread_1_seq_2.277.882167495 RECID=13 STAMP=882167494 archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_12/thread_1_seq_3.278.882167497 RECID=14 STAMP=882167497 archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_12/thread_1_seq_4.279.882167777 RECID=15 STAMP=882167776 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-0d comment=NONE Finished Control File Autobackup at 12-JUN-15 released channel: c1 |
- Online redo log backup
Online Redolog는 RMAN을 이용해서 Backup할 수 없다. 이것을 Backup하기에 앞서서 반드시 Archiving 되어야 한다. 즉 다음과 같은 sql command를 이용하여 Backup을 한다.
| RMAN> run { 2> allocate channel c1 type disk; 3> sql “alter system archive log current”; 4> backup 5> format ‘/oracle/backup/log_%U_%T’ 6> (archivelog from time ‘sysdate-1’ all delete input); 7> release channel c1; 8> } allocated channel: c1 channel c1: SID=39 instance=XXXDB1 device type=DISK sql statement: alter system archive log current Starting backup at 12-JUN-15 current log archived channel c1: starting archived log backup set channel c1: specifying archived log(s) in backup set input archived log thread=2 sequence=5 RECID=1 STAMP=882097839 input archived log thread=1 sequence=33 RECID=7 STAMP=882156401 input archived log thread=2 sequence=6 RECID=2 STAMP=882097840 channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/log_13q99kkh_1_1_20150612 tag=TAG20150612T064744 comment=NONE channel c1: backup set complete, elapsed time: 00:00:01 channel c1: deleting archived log(s) archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_11/thread_2_seq_5.256.882097839 RECID=1 STAMP=882097839 archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_12/thread_1_seq_33.271.882153957 RECID=7 STAMP=882156401 archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_11/thread_2_seq_6.270.882097841 RECID=2 STAMP=882097840 channel c1: starting archived log backup set channel c1: specifying archived log(s) in backup set input archived log thread=1 sequence=5 RECID=16 STAMP=882168463 input archived log thread=1 sequence=6 RECID=17 STAMP=882168464 channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/log_14q99kkj_1_1_20150612 tag=TAG20150612T064744 comment=NONE channel c1: backup set complete, elapsed time: 00:00:01 channel c1: deleting archived log(s) archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_12/thread_1_seq_5.279.882168463 RECID=16 STAMP=882168463 archived log file name=+DG_ARCH/XXXDB/ARCHIVELOG/2015_06_12/thread_1_seq_6.278.882168465 RECID=17 STAMP=882168464 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-0e comment=NONE Finished Control File Autobackup at 12-JUN-15 released channel: c1 |
-
Incremental backupArchivelog mode 인 경우 open 상태에서 database, tablespace, datafile 단위에서 incremental backup 이 가능하다. 즉 parent incremental backup 의 SCN 과 비교해서 큰 block 만을 copy 한다. incremental 은 differential incremental 과 cumulative incremental 로 나뉜다. default 는 differential 이다.
만약 recovery time 이 disk space 보다 중요한 고려사항이라면 cumulative backup 이 differential backup 보다 유리하다.
-
Incremental backup 수행아래 예제는 level 0으로 데이터베이스 전체를 백업 받는 내용 이다. Filesperset 파라미터는 backup file에 최대 4개의 데이터 파일씩 백업 받도록 하는 파라미터이다
-
- 10g 이상부터는 block change tracking 을 enable 시키면 datafile 을 full scan 하지 않고서도 변경된 block 을 tracking 할 수 있으므로 backup 시 성능향상을 꾀할 수 있다.
- Level N incremental Backup은 가장 최근의 N 또는 N보다 작은 Backup이후의 변경된 부분만을 Backup하는 것이다. List Backup Set을 조회해 보면 Type Column에는 ‘Incr’, LV Column에는 ‘0’이라고 나타날 것이다.
| RMAN> run { 2> allocate channel c1 type disk; 3> backup 4> tag full_level0 5> incremental level 0 6> filesperset 4 7> format ‘/oracle/backup/full_level0_%U_%T’ 8> (database); 9> release channel c1; 10> } allocated channel: c1 channel c1: SID=36 instance=XXXDB1 device type=DISK Starting backup at 12-JUN-15 channel c1: starting incremental level 0 datafile backup set channel c1: specifying datafile(s) in backup set input datafile file number=00001 name=+DG_DATA/XXXDB/system01.dbf input datafile file number=00005 name=+DG_DATA/XXXDB/users01.dbf input datafile file number=00004 name=+DG_DATA/XXXDB/undotbs201.dbf channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/full_level0_16q9aseg_1_1_20150612 tag=FULL_LEVEL0 comment=NONE channel c1: backup set complete, elapsed time: 00:00:15 channel c1: starting incremental level 0 datafile backup set channel c1: specifying datafile(s) in backup set input datafile file number=00002 name=+DG_DATA/XXXDB/sysaux01.dbf input datafile file number=00003 name=+DG_DATA/XXXDB/undotbs101.dbf channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/full_level0_17q9asf0_1_1_20150612 tag=FULL_LEVEL0 comment=NONE channel c1: backup set complete, elapsed time: 00:00:15 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-0f comment=NONE Finished Control File Autobackup at 12-JUN-15 released channel: c1 |
Backup 내용을 확인 해 보면 Incremental backup을 level 0으로 수행 한 것을 볼 수 있다.
| RMAN> list backupset of database; List of Backup Sets =================== BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 34 Incr 0 272.41M DISK 00:00:07 12-JUN-15 BP Key: 34 Status: AVAILABLE Compressed: NO Tag: FULL_LEVEL0 Piece Name: /oracle/backup/full_level0_16q9aseg_1_1_20150612 List of Datafiles in backup set 34 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 1 0 Incr 1404169 12-JUN-15 +DG_DATA/XXXDB/system01.dbf 4 0 Incr 1404169 12-JUN-15 +DG_DATA/XXXDB/undotbs201.dbf 5 0 Incr 1404169 12-JUN-15 +DG_DATA/XXXDB/users01.dbf BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 35 Incr 0 202.17M DISK 00:00:07 12-JUN-15 BP Key: 35 Status: AVAILABLE Compressed: NO Tag: FULL_LEVEL0 Piece Name: /oracle/backup/full_level0_17q9asf0_1_1_20150612 List of Datafiles in backup set 35 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 2 0 Incr 1404175 12-JUN-15 +DG_DATA/XXXDB/sysaux01.dbf 3 0 Incr 1404175 12-JUN-15 +DG_DATA/XXXDB/undotbs101.dbf |
- Incremental Backup을 이용한 Backup 전략의 예
| 구분 | 내용 |
| Sun night | level 0 backup performed |
| Mon night | level 2 backup performed |
| Tue night | level 2 backup performed |
| Wed night | level 2 backup performed |
| Thu night | level 1 backup performed |
| Fri night | level 2 backup performed |
| Sat night | level 2 backup performed |
만일 Database가 토요일 아침에 Crash가 발생했다고 가정하면 RMAN은 Sunday, Thursday, Friday 의 Backup을 이용하여 Recovery를 할 수 있다. 왜냐하면 Thursday의 level 1 Backup은 Sunday이후의 모든 변화된 내용을 포함하고 있고 Friday의 level 2는 Thursday이후에 모든 변화된 내용을 포함하고 있기 때문이다.
-
Cumulative Incremental BackupCumulative incremental Backup은 가장 최근의 N보다 작은 Backup이후의 변경된 부분만을 Backup하는 것이다.
| RMAN> run { 2> allocate channel c1 type disk; 3> backup 4> tag Inc_level1 5> format ‘/oracle/backup/full_level1_%U_%T’ 6> incremental level 1 cumulative database; 7> release channel c1; 8> } allocated channel: c1 channel c1: SID=36 instance=XXXDB1 device type=DISK Starting backup at 12-JUN-15 channel c1: starting incremental level 1 datafile backup set channel c1: specifying datafile(s) in backup set input datafile file number=00001 name=+DG_DATA/XXXDB/system01.dbf input datafile file number=00002 name=+DG_DATA/XXXDB/sysaux01.dbf input datafile file number=00003 name=+DG_DATA/XXXDB/undotbs101.dbf input datafile file number=00004 name=+DG_DATA/XXXDB/undotbs201.dbf input datafile file number=00005 name=+DG_DATA/XXXDB/users01.dbf channel c1: starting piece 1 at 12-JUN-15 channel c1: finished piece 1 at 12-JUN-15 piece handle=/oracle/backup/full_level1_1bq9b10e_1_1_20150612 tag=INC_LEVEL1 comment=NONE channel c1: backup set complete, elapsed time: 00:00:15 Finished backup at 12-JUN-15 Starting Control File Autobackup at 12-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-11 comment=NONE Finished Control File Autobackup at 12-JUN-15 released channel: c1 |
Backup 내용을 확인 해 보면 Incremental backup을 level 1으로 수행 한 것을 볼 수 있다.
| RMAN> list backupset of database; List of Backup Sets =================== BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 39 Incr 1 6.87M DISK 00:00:13 12-JUN-15 BP Key: 39 Status: AVAILABLE Compressed: NO Tag: INC_LEVEL1 Piece Name: /oracle/backup/full_level1_1bq9b10e_1_1_20150612 List of Datafiles in backup set 39 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 1 1 Incr 1407864 12-JUN-15 +DG_DATA/XXXDB/system01.dbf 2 1 Incr 1407864 12-JUN-15 +DG_DATA/XXXDB/sysaux01.dbf 3 1 Incr 1407864 12-JUN-15 +DG_DATA/XXXDB/undotbs101.dbf 4 1 Incr 1407864 12-JUN-15 +DG_DATA/XXXDB/undotbs201.dbf 5 1 Incr 1407864 12-JUN-15 +DG_DATA/XXXDB/users01.dbf |
-
RMAN 백업 작업 진행 사항 확인하기RMAN 작업을 하다 보면 얼마나 진행되었고 얼마나 남았는지 궁금할 경우가 있다. 이럴 때는 아래의 방법으로 조회하면 결과를 알 수 있다.
| SQL> r 1 SELECT SID, SERIAL#, CONTEXT, SOFAR, TOTALWORK, 2 ROUND(SOFAR/TOTALWORK* 100,2) “%_COMPLETE” 3 FROM V$SESSION_LONGOPS 4 WHERE OPNAME LIKE ‘RMAN%’ 5 AND OPNAME NOT LIKE ‘%aggregate%’ 6 AND TOTALWORK != 0 7* AND SOFAR <> TOTALWORK SID SERIAL# CONTEXT SOFAR TOTALWORK %_COMPLETE ———- ———- ———- ———- ———- ———- 36 37905 1 101613 223360 45.49 SQL> r 1 SELECT SID, SERIAL#, CONTEXT, SOFAR, TOTALWORK, 2 ROUND(SOFAR/TOTALWORK* 100,2) “%_COMPLETE” 3 FROM V$SESSION_LONGOPS 4 WHERE OPNAME LIKE ‘RMAN%’ 5 AND OPNAME NOT LIKE ‘%aggregate%’ 6 AND TOTALWORK != 0 7* AND SOFAR <> TOTALWORK SID SERIAL# CONTEXT SOFAR TOTALWORK %_COMPLETE ———- ———- ———- ———- ———- ———- 36 37905 1 180526 223360 80.82 SQL> r 1 SELECT SID, SERIAL#, CONTEXT, SOFAR, TOTALWORK, 2 ROUND(SOFAR/TOTALWORK* 100,2) “%_COMPLETE” 3 FROM V$SESSION_LONGOPS 4 WHERE OPNAME LIKE ‘RMAN%’ 5 AND OPNAME NOT LIKE ‘%aggregate%’ 6 AND TOTALWORK != 0 7* AND SOFAR <> TOTALWORK no rows selected à작업이 완료되면 no rows selected 로 나타남. |
-
Recovery
- Datafile 장애 복구
- Datafile 장애 복구
- 장애 발생 예제
ASM DISK Group은 Online 중에는 아래와 같이 삭제 되지 않는다.
| ASMCMD [+DG_DATA/XXXDB] > rm users01.dbf ORA-15032: not all alterations performed ORA-15028: ASM file ‘+DG_DATA/XXXDB/users01.dbf’ not dropped; currently being accessed (DBD ERROR: OCIStmtExecute) |
Instance shutdown 이후 삭제를 진행 한다.
| SQL> shutdown immediate Database closed. Database dismounted. ORACLE instance shut down. |
USERS TABLESPACE의 datafile을 삭제 한다.
| ASMCMD [+DG_DATA/XXXDB] > rm users01.dbf |
Datafile이 없으므로 mount 상태에서 open 되지 않는다. 5번 datafile이 깨지거나 삭제되어서 장애가 났음을 확인 할 수 있다.
| SQL> startup ORACLE instance started. Total System Global Area 1157627904 bytes Fixed Size 2923632 bytes Variable Size 855638928 bytes Database Buffers 285212672 bytes Redo Buffers 13852672 bytes Database mounted. ORA-01157: cannot identify/lock data file 5 – see DBWR trace file ORA-01110: data file 5: ‘+DG_DATA/XXXDB/users01.dbf’ |
- Datafile 복구 restore
데이터파일을 restore 한다. 5번 datafile 인 +DG_DATA/XXXDB/users01.dbf 파일을 restore 하는 과정이다. 위에서 백업 했던 incremental Backup의 level 0번을 가지고 restore 한다.
| RMAN> restore datafile 5; Starting restore at 12-JUN-15 using target database control file instead of recovery catalog allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=43 instance=XXXDB1 device type=DISK channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00005 to +DG_DATA/XXXDB/users01.dbf channel ORA_DISK_1: reading from backup piece /oracle/backup/full_level0_16q9aseg_1_1_20150612 channel ORA_DISK_1: piece handle=/oracle/backup/full_level0_16q9aseg_1_1_20150612 tag=FULL_LEVEL0 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:03 Finished restore at 12-JUN-15 |
- Datafile 복구 recover
Restore 한 datafile에 대해 recover를 시행 시켜야 한다. 예제에서는 level0 full backup 이후 level1로 incremental backup을 받았는데, 가장 최근의 backup 파일 이므로 level1의 backup piece를 가지고 추가 recover를 시행 한다.
| RMAN> recover datafile 5; Starting recover at 12-JUN-15 using channel ORA_DISK_1 channel ORA_DISK_1: starting incremental datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set destination for restore of datafile 00005: +DG_DATA/XXXDB/users01.dbf channel ORA_DISK_1: reading from backup piece /oracle/backup/full_level1_1dq9b2nk_1_1_20150612 channel ORA_DISK_1: piece handle=/oracle/backup/full_level1_1dq9b2nk_1_1_20150612 tag=INC_LEVEL1 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:01 starting media recovery media recovery complete, elapsed time: 00:00:01 Finished recover at 12-JUN-15 |
- Datafile 복구 Open 및 확인
정상적으로 recover가 되었는지 확인 한다. 정상적으로 +DG_DATA/XXXDB/users01.dbf 파일이 생성된 것을 확인 할 수 있다.
| SQL> alter database open; Database altered. SQL> select instance_name, status from v$instance; INSTANCE_NAME STATUS —————- ———— XXXDB1 OPEN SQL> select name from v$datafile; NAME ——————————————— +DG_DATA/XXXDB/system01.dbf +DG_DATA/XXXDB/sysaux01.dbf +DG_DATA/XXXDB/undotbs101.dbf +DG_DATA/XXXDB/undotbs201.dbf +DG_DATA/XXXDB/users01.dbf |
- Tablespace 장애 복구
위에서 확인 하였던 datafile 장애 복구와 방법은 동일 하다. Restore 및 recover 할 때 tablespce로 복구 하면 된다. 아래 예제는 USERS TABLESPACE에 대해 RMAN script로 복구 하는 방법이다.
- Tablespace 복구
장애가 발생한 users tablespace 에 대해 restore 후 recover 로 복구 하는 내용 이다.
| RMAN> run { 2> RESTORE TABLESPACE users; 3> RECOVER TABLESPACE users; 4> } Starting restore at 12-JUN-15 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=38 instance=XXXDB1 device type=DISK channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00005 to +DG_DATA/XXXDB/users01.dbf channel ORA_DISK_1: reading from backup piece /oracle/backup/full_level0_16q9aseg_1_1_20150612 channel ORA_DISK_1: piece handle=/oracle/backup/full_level0_16q9aseg_1_1_20150612 tag=FULL_LEVEL0 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:01 Finished restore at 12-JUN-15 Starting recover at 12-JUN-15 using channel ORA_DISK_1 channel ORA_DISK_1: starting incremental datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set destination for restore of datafile 00005: +DG_DATA/XXXDB/users01.dbf channel ORA_DISK_1: reading from backup piece /oracle/backup/full_level1_1dq9b2nk_1_1_20150612 channel ORA_DISK_1: piece handle=/oracle/backup/full_level1_1dq9b2nk_1_1_20150612 tag=INC_LEVEL1 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:02 starting media recovery media recovery complete, elapsed time: 00:00:00 Finished recover at 12-JUN-15 |
-
Tablespace 복구 Open 및 확인정상 복구 되었는지 확인 한다. Users tablespace 가 정상적으로 복구 되었는지 확인 한다.
| SQL> alter database open; Database altered. SQL> select instance_name, status from v$instance; INSTANCE_NAME STATUS —————- ———— XXXDB1 OPEN SQL> select name from v$datafile; NAME ——————————————- +DG_DATA/XXXDB/system01.dbf +DG_DATA/XXXDB/sysaux01.dbf +DG_DATA/XXXDB/undotbs101.dbf +DG_DATA/XXXDB/undotbs201.dbf +DG_DATA/XXXDB/users01.dbf |
- Database 장애 복구
가장 최근에 백업한 backupset을 이용하여 database 전체 복구를 진행하는 방법이다. 아래 명령어를 수행하면 mount 까지 올린 상태에서 restore 및 recover 를 수행 한 다음, 데이터베이스를 open 시키는 방식이다.
기본적으로 restore controlfile command에 의하여 init.ora에 지정되어 있는 control_files의 위치로 자동적으로 controlfile들이 restore된다. 이렇게 하지 않고 특정한 위치를 지정하기 위해서는 restore controlfile to ‘filename’ 이라고 지정하면 된다.
| RMAN> RUN { 2> startup mount; 3> RESTORE DATABASE; 4> RECOVER DATABASE; 5> sql ‘ALTER DATABASE OPEN’; 6> } Oracle instance started database mounted Total System Global Area 1157627904 bytes Fixed Size 2923632 bytes Variable Size 855638928 bytes Database Buffers 285212672 bytes Redo Buffers 13852672 bytes Starting restore at 12-JUN-15 using target database control file instead of recovery catalog allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=41 instance=XXXDB1 device type=DISK channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00001 to +DG_DATA/XXXDB/system01.dbf channel ORA_DISK_1: restoring datafile 00004 to +DG_DATA/XXXDB/undotbs201.dbf channel ORA_DISK_1: restoring datafile 00005 to +DG_DATA/XXXDB/users01.dbf channel ORA_DISK_1: reading from backup piece /oracle/backup/full_level0_16q9aseg_1_1_20150612 channel ORA_DISK_1: piece handle=/oracle/backup/full_level0_16q9aseg_1_1_20150612 tag=FULL_LEVEL0 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:25 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00002 to +DG_DATA/XXXDB/sysaux01.dbf channel ORA_DISK_1: restoring datafile 00003 to +DG_DATA/XXXDB/undotbs101.dbf channel ORA_DISK_1: reading from backup piece /oracle/backup/full_level0_17q9asf0_1_1_20150612 channel ORA_DISK_1: piece handle=/oracle/backup/full_level0_17q9asf0_1_1_20150612 tag=FULL_LEVEL0 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:25 Finished restore at 12-JUN-15 Starting recover at 12-JUN-15 using channel ORA_DISK_1 channel ORA_DISK_1: starting incremental datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set destination for restore of datafile 00001: +DG_DATA/XXXDB/system01.dbf destination for restore of datafile 00002: +DG_DATA/XXXDB/sysaux01.dbf destination for restore of datafile 00003: +DG_DATA/XXXDB/undotbs101.dbf destination for restore of datafile 00004: +DG_DATA/XXXDB/undotbs201.dbf destination for restore of datafile 00005: +DG_DATA/XXXDB/users01.dbf channel ORA_DISK_1: reading from backup piece /oracle/backup/full_level1_1dq9b2nk_1_1_20150612 channel ORA_DISK_1: piece handle=/oracle/backup/full_level1_1dq9b2nk_1_1_20150612 tag=INC_LEVEL1 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:07 starting media recovery media recovery complete, elapsed time: 00:00:04 Finished recover at 12-JUN-15 sql statement: ALTER DATABASE OPEN |
- Drop table 후 복구
Drop table이나 drop user, update, delete 장애 등이 이 경우에 해당되며 모두 복구하는 원리는 동일하다. 이 방법에서 가장 중요한 것은 장애 난 시점의 시간인데 그 시간을 확인한 후 복구를 진행한다. 예로 test01 table을 생성 하고 drop 한 뒤 복구를 진행한다.
- Test table 생성
| SQL> set line 200 SQL> col tablespace_name for a10 SQL> col file_name for a50 SQL> select tablespace_name, bytes/1024/1024 MB, file_name from dba_data_files; TABLESPACE MB FILE_NAME ———- ———- ————————————————– SYSTEM 700 +DG_DATA/XXXDB/system01.dbf SYSAUX 550 +DG_DATA/XXXDB/sysaux01.dbf UNDOTBS1 290 +DG_DATA/XXXDB/undotbs101.dbf UNDOTBS2 200 +DG_DATA/XXXDB/undotbs201.dbf USERS 5 +DG_DATA/XXXDB/users01.dbf SQL> conn wmsuser/wmsuser Connected. SQL> create table test01 (no number) tablespace users; Table created. à테스트 유저인 wmsuser에서 test01 이라는 테이블을 생성한다. SQL> insert into test01 values(1); 1 row created. SQL> insert into test01 values(2); 1 row created. SQL> commit; Commit complete. à총2건의 데이터를 insert 한다. SQL> select * from test01; NO ———- 1 2 SQL> select to_char(sysdate, ‘YYYY-MM-DD:HH24:MI:SS’) 2 from dual; TO_CHAR(SYSDATE,’YY ——————- 2015-06-12:21:56:00 à위 시간까지 테이블이 존재하는 시간이다. |
- Test table 삭제
테스트를 위해 위에서 생성한 table을 삭제 한다.
| SQL> drop table test01 purge; Table dropped. SQL> select * from test01; select * from test01 * ERROR at line 1: ORA-00942: table or view does not exist à해당 테이블을 삭제하여 조회가 되지 않는다. |
- Test table 복구
DB를 정상 종료 시킨 후 해당 시간으로 복구를 진행하여, 위에서 삭제된 테이블을 복구 시킨다. Set until time은 그 시점까지 복구 하겠다는 의미이다. 이 시간은 위에서 테이블을 삭제 하기 전 시간이다.
이 방법에서 가장 핵심은 set until time 부분과 그 윗부분에 NLS_DATE_FORMAT 설정하는 부분이다. Drop table만 예로 했지만 drop user나 DML 장애 시에도 같은 방법으로 복구하면 된다.
| RMAN> run { 2> startup mount; 3> sql ‘alter session set nls_date_format=”YYYY-MM-DD:HH24:MI:SS”‘; 4> set until time=’2015-06-12:21:56:00′; 5> restore database; 6> recover database; 7> alter database open resetlogs; 8> } Oracle instance started database mounted Total System Global Area 1157627904 bytes Fixed Size 2923632 bytes Variable Size 855638928 bytes Database Buffers 285212672 bytes Redo Buffers 13852672 bytes using target database control file instead of recovery catalog sql statement: alter session set nls_date_format=”YYYY-MM-DD:HH24:MI:SS” executing command: SET until clause Starting restore at 12-JUN-15 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=41 instance=XXXDB1 device type=DISK channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00001 to +DG_DATA/XXXDB/system01.dbf channel ORA_DISK_1: restoring datafile 00004 to +DG_DATA/XXXDB/undotbs201.dbf channel ORA_DISK_1: restoring datafile 00005 to +DG_DATA/XXXDB/users01.dbf channel ORA_DISK_1: reading from backup piece /oracle/backup/full_level0_16q9aseg_1_1_20150612 channel ORA_DISK_1: piece handle=/oracle/backup/full_level0_16q9aseg_1_1_20150612 tag=FULL_LEVEL0 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:25 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00002 to +DG_DATA/XXXDB/sysaux01.dbf channel ORA_DISK_1: restoring datafile 00003 to +DG_DATA/XXXDB/undotbs101.dbf channel ORA_DISK_1: reading from backup piece /oracle/backup/full_level0_17q9asf0_1_1_20150612 channel ORA_DISK_1: piece handle=/oracle/backup/full_level0_17q9asf0_1_1_20150612 tag=FULL_LEVEL0 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:15 Finished restore at 12-JUN-15 Starting recover at 12-JUN-15 using channel ORA_DISK_1 channel ORA_DISK_1: starting incremental datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set destination for restore of datafile 00001: +DG_DATA/XXXDB/system01.dbf destination for restore of datafile 00002: +DG_DATA/XXXDB/sysaux01.dbf destination for restore of datafile 00003: +DG_DATA/XXXDB/undotbs101.dbf destination for restore of datafile 00004: +DG_DATA/XXXDB/undotbs201.dbf destination for restore of datafile 00005: +DG_DATA/XXXDB/users01.dbf channel ORA_DISK_1: reading from backup piece /oracle/backup/full_level1_1dq9b2nk_1_1_20150612 channel ORA_DISK_1: piece handle=/oracle/backup/full_level1_1dq9b2nk_1_1_20150612 tag=INC_LEVEL1 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:07 starting media recovery media recovery complete, elapsed time: 00:00:09 Finished recover at 12-JUN-15 Statement processed |
- Test table 복구 확인
정상적으로 위에서 삭제한 테이블이 복구 되었는지 확인 한다.
| SQL> select * from test01; NO ———- 1 2 |
- Drop tablespace 복구
사용자가 명령어로 수행 시킨 tablespace를 복구 시키는 방법 이다.
- Drop tablespace test 현재 상태 확인
현재 DB 상태를 확인 한다.
| SQL> set line 200 SQL> col tablespace_name for a10 SQL> col file_name for a50 SQL> select tablespace_name, bytes/1024/1024 MB, file_name 2 from dba_data_files; TABLESPACE MB FILE_NAME ———- ———- ————————————————– SYSTEM 700 +DG_DATA/XXXDB/system01.dbf SYSAUX 550 +DG_DATA/XXXDB/sysaux01.dbf UNDOTBS1 290 +DG_DATA/XXXDB/undotbs101.dbf UNDOTBS2 200 +DG_DATA/XXXDB/undotbs201.dbf USERS 5 +DG_DATA/XXXDB/users01.dbf |
- Drop tablespace test 용 테이블스페이스 생성
테스트를 위해 임시로 테이블 스페이스를 하나 생성한다.
| SQL> create tablespace test 2 datafile ‘+DG_DATA/XXXDB/test01.dbf’ size 5M; Tablespace created. SQL> select tablespace_name, bytes/1024/1024 MB, file_name 2 from dba_data_files; TABLESPACE MB FILE_NAME ———- ———- ————————————————– SYSTEM 700 +DG_DATA/XXXDB/system01.dbf SYSAUX 550 +DG_DATA/XXXDB/sysaux01.dbf UNDOTBS1 290 +DG_DATA/XXXDB/undotbs101.dbf UNDOTBS2 200 +DG_DATA/XXXDB/undotbs201.dbf USERS 5 +DG_DATA/XXXDB/users01.dbf TEST 5 +DG_DATA/XXXDB/test01.dbf |
- Drop tablespace test 전체 백업
해당 데이터베이스에 대해 전체 백업을 수행 한다.
| RMAN> run { 2> allocate channel c1 type disk; 3> backup 4> tag full_level0 5> incremental level 0 6> filesperset 4 7> format ‘/oracle/backup/full_level0_%U_%T’ 8> (database); 9> release channel c1; 10> } using target database control file instead of recovery catalog allocated channel: c1 channel c1: SID=69 instance=XXXDB1 device type=DISK Starting backup at 13-JUN-15 channel c1: starting incremental level 0 datafile backup set channel c1: specifying datafile(s) in backup set input datafile file number=00001 name=+DG_DATA/XXXDB/system01.dbf input datafile file number=00005 name=+DG_DATA/XXXDB/users01.dbf input datafile file number=00006 name=+DG_DATA/XXXDB/test01.dbf input datafile file number=00004 name=+DG_DATA/XXXDB/undotbs201.dbf channel c1: starting piece 1 at 13-JUN-15 channel c1: finished piece 1 at 13-JUN-15 piece handle=/oracle/backup/full_level0_1jq9c7ql_1_1_20150613 tag=FULL_LEVEL0 comment=NONE channel c1: backup set complete, elapsed time: 00:00:15 channel c1: starting incremental level 0 datafile backup set channel c1: specifying datafile(s) in backup set input datafile file number=00002 name=+DG_DATA/XXXDB/sysaux01.dbf input datafile file number=00003 name=+DG_DATA/XXXDB/undotbs101.dbf channel c1: starting piece 1 at 13-JUN-15 channel c1: finished piece 1 at 13-JUN-15 piece handle=/oracle/backup/full_level0_1kq9c7r5_1_1_20150613 tag=FULL_LEVEL0 comment=NONE channel c1: backup set complete, elapsed time: 00:00:15 Finished backup at 13-JUN-15 Starting Control File Autobackup at 13-JUN-15 piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150613-00 comment=NONE Finished Control File Autobackup at 13-JUN-15 released channel: c1 |
- Drop tablespace test 용 테이블 및 데이터 입력
테스트를 위해 테이블 생성 및 데이터를 입력 한다. 위에서 생성한 테스트용 테이블 스페이스에 테이블을 생성 한다.
| SQL> create table test02 (no number) tablespace test; Table created. SQL> insert into test02 values (1); 1 row created. SQL> insert into test02 values (2); 1 row created. SQL> commit; SQL> @time TO_CHAR(SYSDATE,’YY ——————- 2015-06-13:06:30:14 à위 시간까지는 해당 테이블 스페이스가 존재 한다. |
- Drop tablespace test 테이블스페이스 장애 발생
사용자가 실수로 해당 테이블스페이스를 삭제 한 내용이다. Drop tablespace 명령어를 사용하였다면 해당 데이터베이스의 alert log에 시간이 찍힌다.
| SQL> drop tablespace test including contents and datafiles; Tablespace dropped. àalert log 확인 Sat Jun 13 06:31:11 2015 à 위시간 이전까지 테이블 스페이스가 존재 함. drop tablespace test including contents and datafiles Sat Jun 13 06:31:14 2015 Deleted file +DG_DATA/XXXDB/test01.dbf Completed: drop tablespace test including contents and datafiles |
- Drop tablespace test 복구 시작
데이터베이스를 정상 기동 시킨 후, 가장 최근의 control file을 restore 한 후, 테이블 스페이스 삭제 전까지 복구를 진행 하면 된다. nls_date_format을 사용하여 NLS format 변경 후 위에서 확인 하였던 drop tablespace 전의 시간까지 복구를 진행 하면 된다. 아래 내용을 확인 하면 archive log file까지 적용하여 데이터까지 복구 된 것을 확인 할 수 있다.
| RMAN> run { 2> startup nomount; 3> restore controlfile from ‘/oracle/12.1.0.2/dbs/c-611517755-20150613-00’; 4> sql ‘ALTER DATABASE MOUNT’; 5> sql ‘alter session set nls_date_format=”YYYY-MM-DD:HH24:MI:SS”‘; 6> set until time=’2015-06-13:06:31:09′; 7> restore database; 8> recover database; 9> alter database open resetlogs; 10> } Oracle instance started Total System Global Area 1157627904 bytes Fixed Size 2923632 bytes Variable Size 855638928 bytes Database Buffers 285212672 bytes Redo Buffers 13852672 bytes Starting restore at 13-JUN-15 using target database control file instead of recovery catalog allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=41 instance=XXXDB1 device type=DISK channel ORA_DISK_1: restoring control file channel ORA_DISK_1: restore complete, elapsed time: 00:00:03 output file name=+DG_DATA/XXXDB/control01.ctl output file name=+DG_DATA/XXXDB/control02.ctl Finished restore at 13-JUN-15 sql statement: ALTER DATABASE MOUNT released channel: ORA_DISK_1 sql statement: alter session set nls_date_format=”YYYY-MM-DD:HH24:MI:SS” executing command: SET until clause Starting restore at 13-JUN-15 allocated channel: ORA_DISK_1 channel ORA_DISK_1: SID=41 instance=XXXDB1 device type=DISK channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00001 to +DG_DATA/XXXDB/system01.dbf channel ORA_DISK_1: restoring datafile 00004 to +DG_DATA/XXXDB/undotbs201.dbf channel ORA_DISK_1: restoring datafile 00005 to +DG_DATA/XXXDB/users01.dbf channel ORA_DISK_1: restoring datafile 00006 to +DG_DATA/XXXDB/test01.dbf channel ORA_DISK_1: reading from backup piece /oracle/backup/full_level0_1jq9c7ql_1_1_20150613 channel ORA_DISK_1: piece handle=/oracle/backup/full_level0_1jq9c7ql_1_1_20150613 tag=FULL_LEVEL0 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:25 channel ORA_DISK_1: starting datafile backup set restore channel ORA_DISK_1: specifying datafile(s) to restore from backup set channel ORA_DISK_1: restoring datafile 00002 to +DG_DATA/XXXDB/sysaux01.dbf channel ORA_DISK_1: restoring datafile 00003 to +DG_DATA/XXXDB/undotbs101.dbf channel ORA_DISK_1: reading from backup piece /oracle/backup/full_level0_1kq9c7r5_1_1_20150613 channel ORA_DISK_1: piece handle=/oracle/backup/full_level0_1kq9c7r5_1_1_20150613 tag=FULL_LEVEL0 channel ORA_DISK_1: restored backup piece 1 channel ORA_DISK_1: restore complete, elapsed time: 00:00:25 Finished restore at 13-JUN-15 Starting recover at 13-JUN-15 using channel ORA_DISK_1 starting media recovery archived log for thread 1 with sequence 3 is already on disk as file +DG_DATA/XXXDB/redo01.log archived log file name=+DG_DATA/XXXDB/redo01.log thread=1 sequence=3 media recovery complete, elapsed time: 00:00:06 Finished recover at 13-JUN-15 Statement processed |
- Drop tablespace test 최종 확인
| SQL> set line 200 SQL> col tablespace_name for a10 SQL> col file_name for a50 SQL> select tablespace_name, bytes/1024/1024 MB, file_name 2 from dba_data_files; TABLESPACE MB FILE_NAME ———- ———- ————————————————– SYSTEM 700 +DG_DATA/XXXDB/system01.dbf SYSAUX 550 +DG_DATA/XXXDB/sysaux01.dbf UNDOTBS1 290 +DG_DATA/XXXDB/undotbs101.dbf UNDOTBS2 200 +DG_DATA/XXXDB/undotbs201.dbf USERS 5 +DG_DATA/XXXDB/users01.dbf TEST 5 +DG_DATA/XXXDB/test01.dbf 6 rows selected. SQL> select * from test02; NO ———- 1 2 |
-
RMAN 관리하기RMAN에 등록되어 있는 backupset등을 수작업을 통해 정리 할 필요가 생길 수도 있다. 아래 내용들은 RMAN의 정보를 동기화 및 정리 하는 방법 들이다.
- Crosscheck
- Crosscheck
| RMAN> crosscheck backup; using channel ORA_DISK_1 crosschecked backup piece: found to be ‘AVAILABLE’ backup piece handle=/oracle/12.1.0.2/dbs/01q97fn1_1_1 RECID=1 STAMP=882097890 crosschecked backup piece: found to be ‘AVAILABLE’ backup piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-00 RECID=2 STAMP=882156448 crosschecked backup piece: found to be ‘AVAILABLE’ backup piece handle=/oracle/backup/05q99aih_1_1_20150612 RECID=3 STAMP=882158161 |
만약 해당 backupset을 물리적으로(OS) 삭제 한 후 다시 crosscheck 수행을 해 보았다. 내용 중에서 파일이 삭제된 마지막 backupset을 보면 상태가 EXPIRED로 보인다. 이것은 backupset 목록에는 있는데 실제 백업 파일이 삭제되고 없다는 의미로 문제가 있음을 나타낸다. 즉 백업 파일을 지울 때도 RMAN 명령어로 삭제해야 하는데 그렇지 않고 0S 명령어로 삭제할 경우 이런 문제가 발생한다. 이럴 경우 backupset에서 EXPIRED 된 목록을 삭제해야 한다.
| RMAN> crosscheck backup; using channel ORA_DISK_1 crosschecked backup piece: found to be ‘AVAILABLE’ backup piece handle=/oracle/12.1.0.2/dbs/01q97fn1_1_1 RECID=1 STAMP=882097890 crosschecked backup piece: found to be ‘AVAILABLE’ backup piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-00 RECID=2 STAMP=882156448 crosschecked backup piece: found to be ‘EXPIRED’ backup piece handle=/oracle/backup/05q99aih_1_1_20150612 RECID=3 STAMP=882158161 |
- Delete expired backupset;
backupset에서 expired 된 목록을 삭제 하는 방법이다. EXPIRED된 목록이 나오면서 삭제 할것인지 선택 하는 부분이 나온다. 삭제를 선택 하면 RMAN 정보에서 삭제된 것을 알 수 있다.
| RMAN> delete expired backupset; using channel ORA_DISK_1 List of Backup Pieces BP Key BS Key Pc# Cp# Status Device Type Piece Name ——- ——- — — ———– ———– ———- 3 3 1 1 EXPIRED DISK /oracle/backup/05q99aih_1_1_20150612 Do you really want to delete the above objects (enter YES or NO)? y deleted backup piece backup piece handle=/oracle/backup/05q99aih_1_1_20150612 RECID=3 STAMP=882158161 Deleted 1 EXPIRED objects |
- Delete
특정 backup set을 삭제하고자 할 대 사용하는 명령어이다.
- Backupset 목록 확인
현재 backup set 목록을 확인 한다.
| RMAN> list backupset; List of Backup Sets =================== BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 1 Full 467.06M DISK 00:00:18 11-JUN-15 BP Key: 1 Status: AVAILABLE Compressed: NO Tag: TAG20150611T111129 Piece Name: /oracle/12.1.0.2/dbs/01q97fn1_1_1 List of Datafiles in backup set 1 File LV Type Ckp SCN Ckp Time Name —- — —- ———- ——— —- 1 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/system01.dbf 2 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/sysaux01.dbf 3 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/undotbs101.dbf 4 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/undotbs201.dbf 5 Full 1184537 11-JUN-15 +DG_DATA/XXXDB/users01.dbf BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 2 Full 18.11M DISK 00:00:04 12-JUN-15 BP Key: 2 Status: AVAILABLE Compressed: NO Tag: TAG20150612T032724 Piece Name: /oracle/12.1.0.2/dbs/c-611517755-20150612-00 Control File Included: Ckp SCN: 1288040 Ckp time: 12-JUN-15 |
- 특정 backupset 삭제
목록에서 BS Key 라고 된 곳이 backup set number 이다. 해당 backup set을 삭제하려면 이 번호를 사용해야 한다.
| RMAN> delete backupset 1; using channel ORA_DISK_1 List of Backup Pieces BP Key BS Key Pc# Cp# Status Device Type Piece Name ——- ——- — — ———– ———– ———- 1 1 1 1 AVAILABLE DISK /oracle/12.1.0.2/dbs/01q97fn1_1_1 Do you really want to delete the above objects (enter YES or NO)? Y deleted backup piece backup piece handle=/oracle/12.1.0.2/dbs/01q97fn1_1_1 RECID=1 STAMP=882097890 Deleted 1 objects |
- Backupset 삭제 확인
Backup set number 1이 삭제 되었는지 확인 한다.
| RMAN> list backupset; List of Backup Sets =================== BS Key Type LV Size Device Type Elapsed Time Completion Time ——- —- — ———- ———– ———— ————— 2 Full 18.11M DISK 00:00:04 12-JUN-15 BP Key: 2 Status: AVAILABLE Compressed: NO Tag: TAG20150612T032724 Piece Name: /oracle/12.1.0.2/dbs/c-611517755-20150612-00 Control File Included: Ckp SCN: 1288040 Ckp time: 12-JUN-15 |
- Delete obsolete
RMAN은 보존 정책에 의해 폐기된 것으로 표시된 백업을 자동으로 삭제하지 않는다. 대신 RMAN은 이러한 백업을 REPORT OBSOLETE 출력 및 V$BACKUP_FILES의 OBSOLETE 컬럼에 OBSOLETE로 표시한다. RMAN은 사용자가 DELETE OBSOLETE 명령을 실행하면 폐기된 파일을 삭제한다.
| RMAN> delete obsolete; RMAN retention policy will be applied to the command RMAN retention policy is set to redundancy 1 using channel ORA_DISK_1 Deleting the following obsolete backups and copies: Type Key Completion Time Filename/Handle ——————– —— —————— ——————– Backup Set 2 12-JUN-15 Backup Piece 2 12-JUN-15 /oracle/12.1.0.2/dbs/c-611517755-20150612-00 Backup Set 4 12-JUN-15 Backup Piece 4 12-JUN-15 /oracle/12.1.0.2/dbs/c-611517755-20150612-01 Backup Set 5 12-JUN-15 Backup Piece 5 12-JUN-15 /oracle/backup/07q99aub_1_1_20150612 Backup Set 6 12-JUN-15 Backup Piece 6 12-JUN-15 /oracle/12.1.0.2/dbs/c-611517755-20150612-02 Backup Set 7 12-JUN-15 Backup Piece 7 12-JUN-15 /oracle/backup/manual/0aq99b12_1_1_20150612 Do you really want to delete the above objects (enter YES or NO)? Y deleted backup piece backup piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-00 RECID=2 STAMP=882156448 deleted backup piece backup piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-01 RECID=4 STAMP=882158164 deleted backup piece backup piece handle=/oracle/backup/07q99aub_1_1_20150612 RECID=5 STAMP=882158540 deleted backup piece backup piece handle=/oracle/12.1.0.2/dbs/c-611517755-20150612-02 RECID=6 STAMP=882158543 deleted backup piece backup piece handle=/oracle/backup/manual/0aq99b12_1_1_20150612 RECID=7 STAMP=882158626 Deleted 5 objects |
-
Oracle Database 정기점검 Checklist
-
일일 Checklist
- DATABASE
- DATABASE
-
- 매일 alert_SID.log 파일의 내용과 trace file의 내용을 체크한다. 이 파일에서 internal error나 다른 oracle error들을 알 수 있다. 이 파일의 내용은 무한히 커지므로 이 파일이 위치한 file system 공간도 체크 할 필요가 있다.
- alert_SID.log 파일이나 trace 파일 일정 크기 이상이 되면 backup을 받는다. alert_SID.ora는 무한히 커지므로 적당한 양만큼 backup을 받는다. 이 파일로 장애 발생의 유추가 가능하므로 일정 기간 이상은 보존이 필요하다.
- Diagnostic dest 의 free space여부를 항상 확인한다.
- 각 tablespace에 free space를 생성되는 속도를 확인한다. 즉, database의 성장 속도를 확인하여 space 부족으로 생길 수 있는 DB가 hang이 걸리는 문제를 미리 대비할 수 있도록 한다.
- Control file
- 매일 control file backup을 받았는지 alert_SID.log에서 확인 한다.
- Online Redo Log file
- log switch interval을 체크한다. Log Switch가 너무 자주 발생하면 Disk I/O에 영향이 있을 수 있고, 심해지면 DB hang이 걸릴 수 있다.
- checkpoint 간격을 자주 확인하라. 권할 만한 checkpoint의 간격은 매 10에서 15분 정도이다. 이 checkpoint의 간격은 Background process가 죽어서 instance가 abort되는 극한 상황에서 database를 살리고 잠깐의 시간 동안 crash recovery를 할 때 반영된다. 위의 간격을 조절하려면 database에서 checkpoint interval setting 또는 checkpoint_timeout을 조절함에 의해 가능하다. checkpoint_timeout을 0으로 그리고 checkpoint_interval을 online redo log file의 크기보다 크게 두면 checkpoint는 log switch가 일어날 때마다 발생한다. 잦은 checkpoint는 crash recovery의 기간은 줄여주나 dirty buffers를 자주 쓰는 것과 file headers를 자주 update하는데 드는 overhead가 발생한다.
- Archived log (Archive log Mode로 운영 시에만 해당됩니다.)
- archive file이 생성되는 destination에 여유 공간이 있도록 유지한다. XXXDB의 경우에는 DG_ARCH disk group을 확인해야 하며, 여유 공간이 없을 시 DB Hang이 발생 할 수 있다.
-
alert.log에 Archive log들에 관한 error가 있는지 확인하라.
- 주 단위 Checklist
- UNDO tablespace에 충분한 공간을 확보하여 ORA-1555 error를 피한다. ORA-1555에러는 Undo 공간이 부족해서 발생하면 발생하지만, bad query로도 유발될 수 있다.
- SYSTEM tablespace 내에 다른 일반 사용자의 object들이나 temporary segments가 있는지 확인한다.
-
OS의 운영 상태를 확인할 수 있는 통계를 만들어서 관리한다.
- 월 단위 Checklist
- 월 단위 지표 별 DB성능증감 추이를 만들어 관리한다.
- 6개월에 한 번씩 recovery test를 한다. 장애가 발생할 때 대처할 수 있는 속도를 증가시키는 의미에서 6개월에 한번씩 recovery test가 필요하다.
-
ASM Disk Path 변경 방법
-
XXXDB stop (Node:1)
-
| $ srvctl stop database -d XXXDB |
-
DG_DATA, DG_ARCH Multi-Path Change Owner (Node:Both)
| # chown grid:dba /dev/sddlmaa2 # chown grid:dba /dev/sddlmab1 |
-
DG_DATA, DG_ARCH Diskgroup Stop (Node:1)
| $ srvctl stop diskgroup -g DG_DATA $ srvctl stop diskgroup -g DG_ARCH |
-
DG_DATA, DG_ARCH Single-Path Change Owner (Node:Both)
| # chown root:disk /dev/sdb2 # chown root:disk /dev/sdc1 |
-
DG_DATA, DG_ARCH Diskgroup Start & Check (Node:1)
| # srvctl start diskgroup -g DG_DATA # srvctl start diskgroup -g DG_ARCH |
-
XXXDB Start & Check & Stop (Node:1)
| $ srvctl start database -d XXXDB $ crs_stat –t $ crsctl stat res –t – alert log check $ srvctl stop database -d XXXDB |
-
OCR & Vote Migration (Node:1)
| # /grid/12.1.0.2/bin/ocrcheck # /grid/12.1.0.2/bin/ocrconfig -add +DG_ARCH # /grid/12.1.0.2/bin/ocrconfig -delete +DG_CRS # /grid/12.1.0.2/bin/ocrcheck # /grid/12.1.0.2/bin/crsctl query css votedisk # /grid/12.1.0.2/bin/crsctl replace votedisk +DG_ARCH # /grid/12.1.0.2/bin/crsctl query css votedisk |
-
CRS Stop (Node : Both)
| # /grid/12.1.0.2/bin/crsctl stop crs |
-
DG_CRS Multi & Single Path Change Ownership (Node:Both)
| # chown grid:dba /dev/sddlmaa1 # chown root:disk /dev/sdb1 |
-
CRS Stat (Node:Both)
| # /grid/12.1.0.2/bin/crsctl start crs |
-
OCR & Vote Migration (Node:1)
| # /grid/12.1.0.2/bin/ocrcheck # /grid/12.1.0.2/bin/ocrconfig -add +DG_CRS # /grid/12.1.0.2/bin/ocrconfig -delete +DG_ARCH # /grid/12.1.0.2/bin/crsctl query css votedisk # /grid/12.1.0.2/bin/crsctl replace votedisk +DG_CRS # /grid/12.1.0.2/bin/crsctl query css votedisk |
-
XXXDB Start & Check (Node:1)
| $ srvctl start database -d XXXDB $ crs_stat -t $ crsctl stat res –t – alert log check |
-
/etc/rc.d/rc.local modify (Both)
| # vi /etc/rc.d/rc.local chown grid:dba /dev/sddlmaa1 chown grid:dba /dev/sddlmaa2 chown grid:dba /dev/sddlmab1 # chmod +x /etc/rc.d/rc.local |
-
Server Reboot & Device Ownership Check (Both)
| /grid/12.1.0.2/bin/crsctl stop crs Reboot |
-
11g R2 이상버전에서 사설 네트워크 정보를 수정하는 방법
11.2 이상의 그리드 인프라스트럭처에서, 사설 네트워크 구성은 OCR에 저장될 뿐만 아니라 gpnp 프로파일에도 저장됩니다.
만약 사설 네트워크가 가용하지 않거나 그 정의가 잘못되었다면, CRSD 프로세스는 기동되지 않을 것이며 OCR에 그 다음의 어떠한 변화도 불가능할 것입니다.
그러므로 사설 네트워크의 구성을 변경할 때는 주의를 기울이는 것이 필요합니다. 올바른 순서로 변경을 수행하는 것은 중요합니다.
또한 gpnp 프로파일의 수동변경은 지원되지 않으니 주의하시기 바랍니다.
수행전에 모든 클러스터 노드에 있는 profile.xml 을 grid 유저로 백업하시기 바랍니다:
| $ cd $GRID_HOME/gpnp/<hostname>/profiles/peer/ $ cp -p profile.xml profile.xml.bk |
-
모든 오라클 클러스터웨어가 기동중인지 확인.
-
grid 유저로 현재의 정보를 얻으시기 바랍니다. 예를 들면
| $ oifcfg getif eth1 100.17.10.0 global public eth0 192.168.0.0 global cluster_interconnect |
* 새로운 cluster_interconnect 정보를 추가합니다:
| $ oifcfg setif -global <interface>/<subnet>:cluster_interconnect |
| For example: a. add a new interface bond0 with the same subnet $ oifcfg setif -global bond0/192.168.0.0:cluster_interconnect b. add a new subnet with the same interface name but different subnet or new interface name $ oifcfg setif -global eth0/192.65.0.0:cluster_interconnect or $ oifcfg setif -global eth3/192.168.1.96:cluster_interconnect |
* 참고사항
| 1. 이것은 인터페이스가 아직 가용하지 않을지라도 -global 옵션을 통해 수행될 수 있습니다. 그러나 만약 인터페이스가 가용하지않다면 이것은 -node 옵션으로는 수행될 수 없으며 이것은노드 이빅션으로 연결될 것입니다. 2. 만약 인터페이스가 그 서버에서 가용하다면 서브넷 주소는 다음의 명령에 의해서 알 수 있습니다. $ oifcfg iflist 그것은 네트워크 인터페이스와 그것의 서브넷 주소의 목록을 보여줍니다. 이 명령은 오라클 클러스터웨어가 기동중이 아닐지라도 수행될 수 있습니다. 서브넷 주소가 x.y.z.0 의 형태가 아닐 수도 있고 x.y.z.24, x.y.z.64 또는 x.y.z.128 등등 일 수도 있음을 주의하십시오. 예를 들면, $ oifcfg iflist lan1 18.1.2.0 lan2 10.2.3.64 << 이것은 사설 네트워크 IP: 10.2.3.86 과 관련있는 사설 네트워크 서브넷 주소입니다 3. 존재하는 사설 네트워크를 대체하는게 아닌 2번째 사설 네트워크를 추가하는 것이라면 두 인터페이스의 MTU 크기가 동일한지 확인하고 그렇지않으면 인스턴스 기동시 에러가 나타날 것입니다. ORA-27504: IPC error creating OSD context ORA-27300: OS system dependent operation:if MTU failed with status: 0 ORA-27301: OS failure message: Error 0 ORA-27302: failure occurred at: skgxpcini2 ORA-27303: additional information: requested interface lan1:801 has a different MTU (1500) than lan3:801 (9000), which is not supported. Check output from ifconfig command |
변경을 확인하십시오:
| $ oifcfg getif |
-
root유저를 통해 모든 노드의 오라클 클러스터웨어를 내리고 비활성화하시기 바랍니다.
| # crsctl stop crs # crsctl disable crs |
-
요구된 사항으로 OS레벨에서 네트워크 구성 변경을 수행하고, 그 변경이후 모든 노드에서 새로운 인터페이스가 가용한지 확인하시기 바랍니다.
| $ ifconfig -a $ ping <private hostname> |
-
오라클 클러스터웨를 활성화하고 root유저로서 모든 노드에서 오라클 클러스터웨어를 재기동하시기 바랍니다.
| # crsctl enable crs # crsctl start crs |
-
필요하다면 기존 인터페이스를 제거하시기 바랍니다.
| $ oifcfg delif -global <if_name>[/<subnet>] eg: $ oifcfg delif -global eth0/192.168.0.0 |
-
주의사항
-
만약 기본적인 네트워크 구성이 변경되었지만 그 동일 변경을 위한 oifcfg 가 수행되지않았다면, 오라클 클러스터웨어가 재기동될 때 CRSD는 기동되지 않을 것입니다.
-
The crsd.log 는 다음과 같을 것입니다:
| 2010-01-30 09:22:47.234: [ default][2926461424] CRS Daemon Starting .. 2010-01-30 09:22:47.273: [ GPnP][2926461424]clsgpnp_Init: [at clsgpnp0.c:837] GPnP client pid=7153, tl=3, f=0 2010-01-30 09:22:47.282: [ OCRAPI][2926461424]clsu_get_private_ip_addresses: no ip addresses found. 2010-01-30 09:22:47.282: [GIPCXCPT][2926461424] gipcShutdownF: skipping shutdown, count 2, from [ clsinet.c : 1732], ret gipcretSuccess (0) 2010-01-30 09:22:47.283: [GIPCXCPT][2926461424] gipcShutdownF: skipping shutdown, count 1, from [ clsgpnp0.c : 1021], ret gipcretSuccess (0) [ OCRAPI][2926461424]a_init_clsss: failed to call clsu_get_private_ip_addr (7) 2010-01-30 09:22:47.285: [ OCRAPI][2926461424]a_init:13!: Clusterware initunsuccessful : [44] 2010-01-30 09:22:47.285: [ CRSOCR][2926461424] OCR context init failure. Error: PROC-44: Error in network address and interface operations Network address and interface operations error [7] 2010-01-30 09:22:47.285: [ CRSD][2926461424][PANIC] CRSD exiting: Could not init OCR, code: 44 2010-01-30 09:22:47.285: [ CRSD][2926461424] Done. |
위의 에러는 OS 설정(oifcfg iflist)과 gpnp 프로파일 설정 profile.xml 간의 부정합을 나타냅니다.
회피방법: OS 네트워크 구성을 원래 상태로 복원하시기 바랍니다. 그리고나서 다시 그 변경을 위한 위의 단계들을 수행하시기 바랍니다.
만약 기본 네트워크가 변경되지 않았지만 oifcfg setif 가 잘못된 서브넷 주소나 인터페이스명을 가지고 수행되었다면 동일한 문제가 일어날 것입니다.
-
클러스터에 어느 한 노드라도 다운되었다면 oifcfg 명령은 다음의 에러와 함께 실패할 것입니다.
| $ oifcfg setif -global bond0/192.168.0.0:cluster_interconnect PRIF-26: Error in update the profiles in the cluster |
회피방법: 기동되어 있지않은 노드의 오라클 클러스터웨어를 기동하시기 바랍니다. 오라클 클러스터웨어가 모든 클러스터 노드에서 기동중인지 확인하시기 바랍니다.
만약 어떤 OS 문제로 그 노드가 다운되었다면 사설 네트워크 변경을 수행하기전에 클러스터로부터 그 노드를 제거하시기 바랍니다.
-
만약 그리드 인프라스트럭처 소유자가 아닌 유저가 위의 명령을 수행하면, 다음과 같은 에러가 발생하며 실패할 것입니다.
| $ oifcfg setif -global bond0/192.168.0.0:cluster_interconnect PRIF-26: Error in update the profiles in the cluster |
회피방법: 그러한 명령을 수행하기위해 그리드 인프라스트럭처 소유자로 로그인하였는지 확인하시기 바랍니다.
-
11.2.0.2 부터, 새로운 인터페이스를 추가하지 않고 마지막 사설 인터페이스(cluster_interconnect)를 지우려고 시도한다면 다음의 에러가 발생.
| PRIF-31: Failed to delete the specified network interface because it is the last private interface |
회피방법: 기존 사설 인터페이스를 지우기전에 우선 새로운 사설 인터페이스를 추가하시기 바랍니다.
-
오라클 클러스터웨어가 노드에서 다운시, 다음의 에러 발생
| $ oifcfg getif PRIF-10: failed to initialize the cluster registry |
회피방법: 그 노드에서 오라클 클러스터웨어를 기동하시기 바랍니다